RPC和HTTP调用对比
现在的公司基本上都是HTTP调用,个别服务会有RPC,突然发现之前自己知道这两个调用方式是不同的,具体有哪些不同还有点模糊,了解了之后发现难怪大厂都用RPC调用,包括gRPC和dubbo。
先说一下他们最本质的区别,就是RPC主要是基于TCP/IP协议的,而HTTP服务主要是基于HTTP协议的,我们都知道HTTP协议是在传输层协议TCP之上的,所以效率来看的话,RPC当然是要更胜一筹啦!当然RPC也可以用HTTP调用,像Feign,不过也因此他被叫做伪RPC。下面来具体说一说RPC服务和HTTP服务。
RPC服务
RPC架构
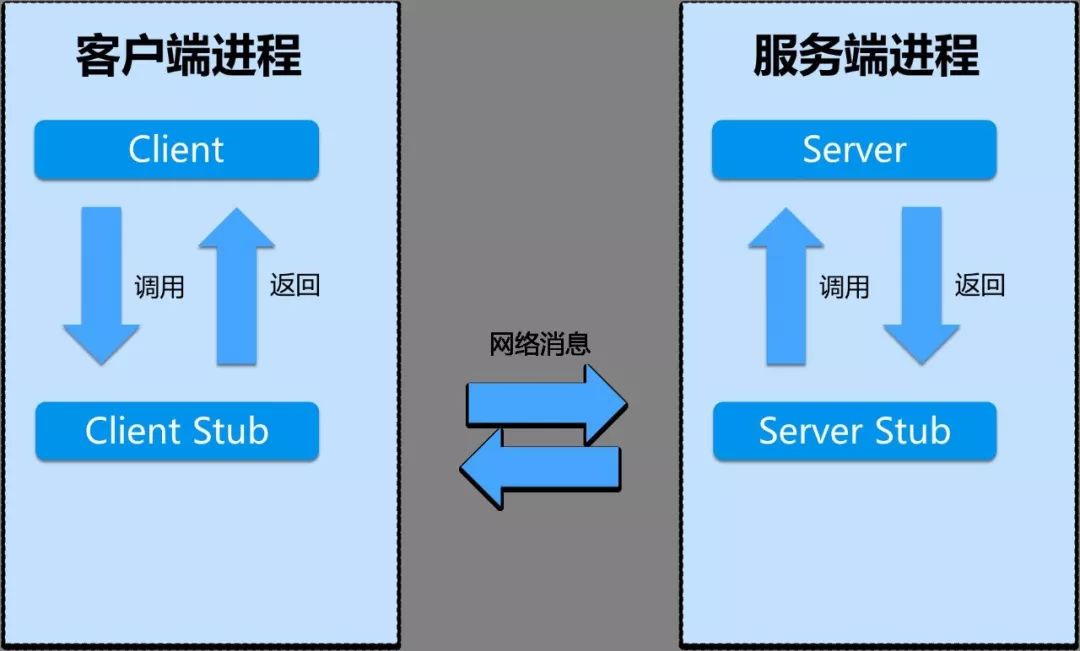
一个完整的RPC架构里面包含了四个核心的组件,分别是Client ,Server,Client Stub以及Server
Stub,这个Stub大家可以理解为存根。分别说说这几个组件:
- 客户端(Client),服务的调用方。
- 服务端(Server),真正的服务提供者。
客户端存根,存放服务端的地址消息,再将客户端的请求参数打包成网络消息,然后通过网络远程发送给服务方。
服务端存根,接收客户端发送过来的消息,将消息解包,并调用本地的方法。
RPC主要是用在大型企业里面,因为大型企业里面系统繁多,业务线复杂,而且效率优势非常重要的一块,这个时候RPC的优势就比较明显了。实际的开发当中是这么做的,项目一般使用maven来管理。
比如我们有一个处理订单的系统服务,先声明它的所有的接口(这里就是具体指Java中的interface),然后将整个项目打包为一个jar包,服务端这边引入这个二方库,然后实现相应的功能,客户端这边也只需要引入这个二方库即可调用了。
为什么这么做?主要是为了减少客户端这边的jar包大小,因为每一次打包发布的时候,jar包太多总是会影响效率。另外也是将客户端和服务端解耦,提高代码的可移植性。
同步调用和异步调用
同步调用就是客户端等待调用执行完成并返回结果。异步调用就是客户端不等待调用执行完成返回结果,不过依然可以通过回调函数等接收到返回结果的通知。如果客户端并不关心结果,则可以变成一个单向的调用。
这个过程有点类似于Java中的callable和runnable接口,我们进行异步执行的时候,如果需要知道执行的结果,就可以使用callable接口,并且可以通过Future类获取到异步执行的结果信息。如果不关心执行的结果,直接使用runnable接口就可以了,因为它不返回结果,当然啦,callable也是可以的,我们不去获取Future就可以了。
流行的RPC框架
- gRPC是Google最近公布的开源软件,基于最新的HTTP2.0协议,并支持常见的众多编程语言。我们知道HTTP2.0是基于二进制的HTTP协议升级版本,目前各大浏览器都在快马加鞭的加以支持。这个RPC框架是基于HTTP协议实现的,底层使用到了Netty框架的支持。下面放两个文档
https://doc.oschina.net/grpc?t=56831
- Thrift是Facebook的一个开源项目,主要是一个跨语言的服务开发框架。它有一个代码生成器来对它所定义的IDL定义文件自动生成服务代码框架。用户只要在其之前进行二次开发就行,对于底层的RPC通讯等都是透明的。不过这个对于用户来说的话需要学习特定领域语言这个特性,还是有一定成本的。
- Dubbo是阿里集团开源的一个极为出名的RPC框架,在很多互联网公司和企业应用中广泛使用。协议和序列化框架都可以插拔是及其鲜明的特色。同样 的远程接口是基于Java Interface,并且依托于spring框架方便开发。可以方便的打包成单一文件,独立进程运行,和现在的微服务概念一致。
http://dubbo.apache.org/zh-cn/docs/user/quick-start.html
关于gRPC和Dubbo暂时可能不会写文章总结,因为文档足够详细,自己也还没看完,等看完了并且有了超出文档的理解再进行总结。
HTTP服务
其实在很久以前,我对于企业开发的模式一直定性为HTTP接口开发,也就是我们常说的RESTful风格的服务接口。的确,对于在接口不多、系统与系统交互较少的情况下,解决信息孤岛初期常使用的一种通信手段;优点就是简单、直接、开发方便。
利用现成的http协议进行传输。我们记得之前实习在公司做后台开发的时候,主要就是进行接口的开发,还要写一大份接口文档,严格地标明输入输出是什么?说清楚每一个接口的请求方法,以及请求参数需要注意的事项等。
接口可能返回一个JSON字符串或者是XML文档。然后客户端再去处理这个返回的信息,从而可以比较快速地进行开发。
但是对于大型企业来说,内部子系统较多、接口非常多的情况下,RPC框架的好处就显示出来了,首先就是长链接,不必每次通信都要像http一样去3次握手什么的,减少了网络开销,虽然HTTP1.1之后也可以长连接了;
其次就是RPC框架一般都有注册中心,有丰富的监控管理;发布、下线接口、动态扩展等,对调用方来说是无感知、统一化的操作。
顺便总结下HTTP版本差别
HTTP 0.9
HTTP 0.9 是一个最古老的版本
- 只支持
GET请求方式:由于不支持其他请求方式,因此客户端是没办法向服务端传输太多的信息 - 没有请求头概念:所以不能在请求中指定版本号,服务端也只具有返回 HTML字符串的能力
- 服务端相响应之后,立即关闭TCP连接
HTTP 1.0
随着 HTTP 1.0 的发布,这个版本:
- 请求方式新增了POST,DELETE,PUT,HEADER等方式
- 增添了请求头和响应头的概念,在通信中指定了 HTTP 协议版本号,以及其他的一些元信息 (比如: 状态码、权限、缓存、内容编码)
- 扩充了传输内容格式,图片、音视频资源、二进制等都可以进行传输
在这个版本主要的就是对请求和响应的元信息进行了扩展,客户端和服务端有更多的获取当前请求的所有信息,进而更好更快的处理请求相关内容。
请求头
一个简单请求的头信息
GET / HTTP/1.0
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5)
Accept: */*
可以看到在请求方法之后有 请求资源的位置 + 请求协议版本,之后是一些客户端的信息配置
响应头
一个简单响应的头信息(v1.0)
HTTP/1.0 200 OK
Content-Type: text/plain
Content-Length: 137582
Expires: Thu, 05 Dec 1997 16:00:00 GMT
Last-Modified: Wed, 5 August 1996 15:55:28 GMT
// 这是一个空行
...数据内容
服务端的响应头第一个就是 请求协议版本,后面紧跟着是这次请求的状态码、以及状态码的描述,之后的内容是一些关于返回内容的描述。
Content-Type
在 HTTP 1.0 的时候,任何的资源都可以被传输,传输的格式呢也是多种多样的,客户端在收到响应体的内容的时候就是根据这个 Content-Type
去进行解析的。所以服务端返回时候必须带着这个字段。
一些常见的 Content-Type 可以参考 对照表。 这些Content-Type 有一个总称叫做MIME type。
关于MIME type,这里想播插一个小插曲:
在 chrome 浏览器中,当跨域请求回来的数据 MIME type 同跨域标签应有的 MIME type 不匹配时,浏览器会启动 CORB
保护数据不被泄漏。被保护的数据有: html、xml、json。(eg: script、img 标签所支持的 MIME
type和他们都不一致),所以服务端在返回资源的时候一定要对应返回正确的Content-Type,以免浏览器屏蔽返回结果。
特性
- 无状态:服务器不跟踪不记录请求过的状态
- 无连接:浏览器每次请求都需要建立tcp连接
无状态
对于无状态的特性可以借助cookie/session机制来做身份认证和状态记录
无连接
无连接导致的性能缺陷有两种:
无法复用连接
每次发送请求,都需要进行一次tcp连接(即3次握手4次挥手),使得网络的利用率非常低队头阻塞
HTTP 1.0 规定在前一个请求响应到达之后下一个请求才能发送,如果前一个阻塞,后面的请求也给阻塞的
HTTP 1.1
HTTP 1.1 是在 1.0 发布之后的半年就推出了,完善了 1.0 版本。目前也还有很多的互联网项目基于 HTTP 1.1 在向外提供服务。
特性
- 长连接:新增Connection字段,可以设置keep-alive值保持连接不断开
- 管道化:基于上面长连接的基础,管道化可以不等第一个请求响应继续发送后面的请求,但响应的顺序还是按照请求的顺序返回
- 缓存处理:新增字段cache-control
- 断点传输
长连接
HTTP 1.1默认保持长连接,数据传输完成保持tcp连接不断开,继续用这个通道传输数据
管道化
基于长连接的基础,我们先看没有管道化请求响应:
tcp没有断开,用的同一个通道
请求1 > 响应1 --> 请求2 > 响应2 --> 请求3 > 响应3
管道化的请求响应:
请求1 --> 请求2 --> 请求3 > 响应1 --> 响应2 --> 响应3
即使服务器先准备好响应2,也是按照请求顺序先返回响应1
虽然管道化,可以一次发送多个请求,但是响应仍是顺序返回,仍然无法解决队头阻塞的问题
缓存处理
当浏览器请求资源时,先看是否有缓存的资源,如果有缓存,直接取,不会再发请求,如果没有缓存,则发送请求。 通过设置字段cache-control来控制缓存。
断点传输
在上传/下载资源时,如果资源过大,将其分割为多个部分,分别上传/下载,如果遇到网络故障,可以从已经上传/下载好的地方继续请求,不用从头开始,提高效率
HTTP 2
2015 年,HTTP/2 发布。HTTP/2 是现行 HTTP 协议(HTTP/1.x)的替代,但它不是重写,HTTP 方法/状态码/语义都与
HTTP/1.x 一样。HTTP/2 基于 SPDY3,专注于 性能 ,最大的一个目标是在用户和网站间只用一个连接(connection)。
HTTP/2 由两个规范(Specification)组成:
Hypertext Transfer Protocol version 2 - RFC7540
HPACK - Header Compression for HTTP/2 - RFC7541
二进制分帧
HTTP/2 采用二进制格式传输数据,而非 HTTP 1.x 的文本格式,二进制协议解析起来更高效。 HTTP / 1
的请求和响应报文,都是由起始行,首部和实体正文(可选)组成,各部分之间以文本换行符分隔。 HTTP/2
将请求和响应数据分割为更小的帧,并且它们采用二进制编码 。
接下来我们介绍几个重要的概念:
- 流:流是连接中的一个虚拟信道,可以承载双向的消息;每个流都有一个唯一的整数标识符(1、2…N);
- 消息:是指逻辑上的 HTTP 消息,比如请求、响应等,由一或多个帧组成。
- 帧:HTTP 2.0 通信的最小单位,每个帧包含帧首部,至少也会标识出当前帧所属的流,承载着特定类型的数据,如 HTTP 首部、负荷,等等
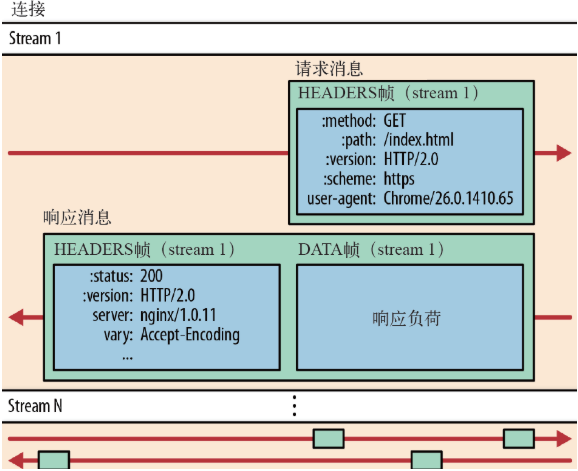
HTTP/2
中,同域名下所有通信都在单个连接上完成,该连接可以承载任意数量的双向数据流。每个数据流都以消息的形式发送,而消息又由一个或多个帧组成。多个帧之间可以乱序发送,根据帧首部的流标识可以重新组装。
多路复用
在 HTTP/2 中引入了多路复用的技术。多路复用很好的解决了浏览器限制同一个域名下的请求数量的问题,同时也接更容易实现全速传输,毕竟新开一个 TCP
连接都需要慢慢提升传输速度。
大家可以通过 该链接 直观感受下 HTTP/2 比 HTTP/1 到底快了多少。

在 HTTP/2 中,有了二进制分帧之后,HTTP /2 不再依赖 TCP 链接去实现多流并行了,在 HTTP/2 中:
- 同域名下所有通信都在单个连接上完成。
- 单个连接可以承载任意数量的双向数据流。
- 数据流以消息的形式发送,而消息又由一个或多个帧组成,多个帧之间可以乱序发送,因为根据帧首部的流标识可以重新组装。
这一特性,使性能有了极大提升:
- 同个域名只需要占用一个 TCP 连接,使用一个连接并行发送多个请求和响应,消除了因多个 TCP 连接而带来的延时和内存消耗。
- 并行交错地发送多个请求,请求之间互不影响。
- 并行交错地发送多个响应,响应之间互不干扰。
- 在 HTTP/2 中,每个请求都可以带一个 31bit 的优先值,0 表示最高优先级, 数值越大优先级越低。有了这个优先值,客户端和服务器就可以在处理不同的流时采取不同的策略,以最优的方式发送流、消息和帧。
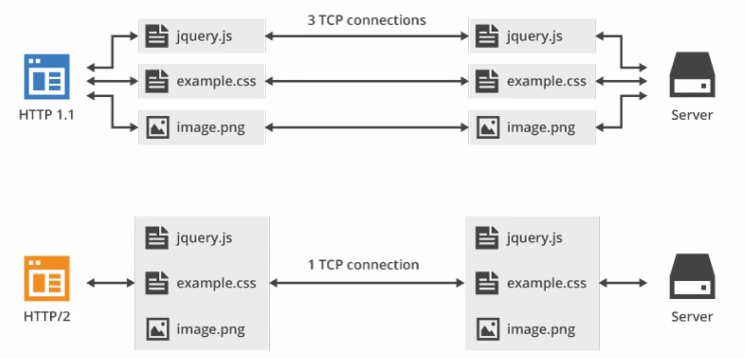
如上图所示,多路复用的技术可以只通过一个 TCP 连接就可以传输所有的请求数据。
头部压缩
在 HTTP/1 中,我们使用文本的形式传输 header,在 header 携带 cookie 的情况下,可能每次都需要重复传输几百到几千的字节。
为了减少这块的资源消耗并提升性能, HTTP/2 对这些首部采取了压缩策略:
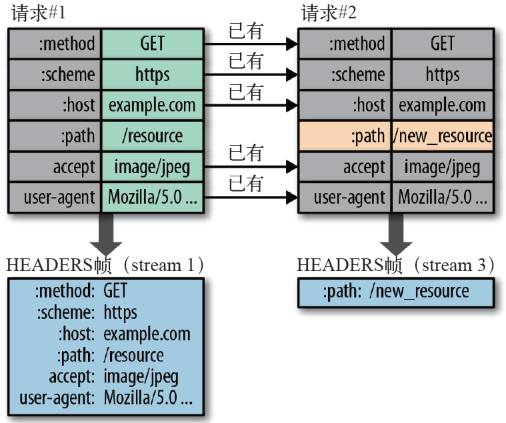
- HTTP/2 在客户端和服务器端使用“首部表”来跟踪和存储之前发送的键-值对,对于相同的数据,不再通过每次请求和响应发送;
- 首部表在 HTTP/2 的连接存续期内始终存在,由客户端和服务器共同渐进地更新;
- 每个新的首部键-值对要么被追加到当前表的末尾,要么替换表中之前的值
例如下图中的两个请求, 请求一发送了所有的头部字段,第二个请求则只需要发送差异数据,这样可以减少冗余数据,降低开销
服务端推送
Server Push 即服务端能通过 push 的方式将客户端需要的内容预先推送过去,也叫“cache push”。
可以想象以下情况,某些资源客户端是一定会请求的,这时就可以采取服务端 push
的技术,提前给客户端推送必要的资源,这样就可以相对减少一点延迟时间。当然在浏览器兼容的情况下你也可以使用 prefetch。
例如服务端可以主动把 JS 和 CSS 文件推送给客户端,而不需要客户端解析 HTML 时再发送这些请求。
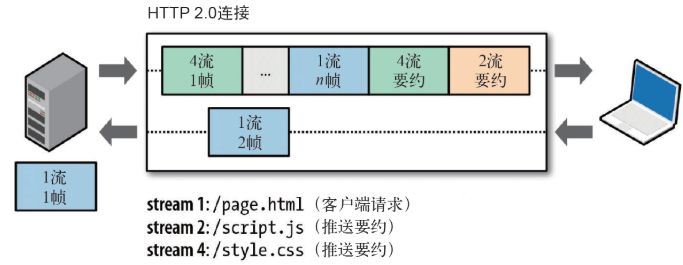
服务端可以主动推送,客户端也有权利选择是否接收。如果服务端推送的资源已经被浏览器缓存过,浏览器可以通过发送 RST_STREAM
帧来拒收。主动推送也遵守同源策略,换句话说,服务器不能随便将第三方资源推送给客户端,而必须是经过双方确认才行。
HTTP3
虽然 HTTP/2 解决了很多之前旧版本的问题,但是它还是存在一个巨大的问题,主要是底层支撑的 TCP 协议造成的。
上文提到 HTTP/2 使用了多路复用,一般来说同一域名下只需要使用一个 TCP 连接。但当这个连接中出现了丢包的情况,那就会导致 HTTP/2
的表现情况反倒不如 HTTP/1 了。
因为在出现丢包的情况下,整个 TCP 都要开始等待重传,也就导致了后面的所有数据都被阻塞了。但是对于 HTTP/1.1 来说,可以开启多个 TCP
连接,出现这种情况反到只会影响其中一个连接,剩余的 TCP 连接还可以正常传输数据。
那么可能就会有人考虑到去修改 TCP 协议,其实这已经是一件不可能完成的任务了。因为 TCP
存在的时间实在太长,已经充斥在各种设备中,并且这个协议是由操作系统实现的,更新起来不大现实。
基于这个原因, Google 就更起炉灶搞了一个基于 UDP 协议的 QUIC 协议,并且使用在了 HTTP/3 上 ,HTTP/3 之前名为
HTTP-over-QUIC,从这个名字中我们也可以发现,HTTP/3 最大的改造就是使用了 QUIC。
QUIC 虽然基于 UDP,但是在原本的基础上新增了很多功能,接下来我们重点介绍几个 QUIC 新功能。
0RTT
通过使用类似 TCP 快速打开的技术,缓存当前会话的上下文,在下次恢复会话的时候,只需要将之前的缓存传递给服务端验证通过就可以进行传输了。 0RTT
建连可以说是 QUIC 相比 HTTP2 最大的性能优势 。那什么是 0RTT 建连呢?
这里面有两层含义:
- 传输层 0RTT 就能建立连接。
- 加密层 0RTT 就能建立加密连接。
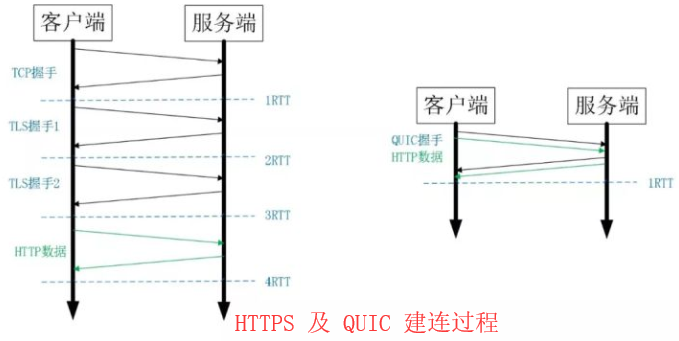
上图左边是 HTTPS 的一次完全握手的建连过程,需要 3 个 RTT。就算是会话复用也需要至少 2 个 RTT。
而 QUIC 呢?由于建立在 UDP 的基础上,同时又实现了 0RTT 的安全握手,所以在大部分情况下,只需要 0 个 RTT
就能实现数据发送,在实现前向加密的基础上,并且 0RTT 的成功率相比 TLS 的会话记录单要高很多。
多路复用
虽然 HTTP/2 支持了多路复用,但是 TCP 协议终究是没有这个功能的。QUIC
原生就实现了这个功能,并且传输的单个数据流可以保证有序交付且不会影响其他的数据流,这样的技术就解决了之前 TCP 存在的问题。
同 HTTP2.0 一样,同一条 QUIC 连接上可以创建多个 stream,来发送多个 HTTP 请求,但是,QUIC 是基于 UDP
的,一个连接上的多个 stream 之间没有依赖。比如下图中 stream2 丢了一个 UDP 包,不会影响后面跟着 Stream3 和
Stream4,不存在 TCP 队头阻塞。虽然 stream2 的那个包需要重新传,但是 stream3、stream4 的包无需等待,就可以发给用户。
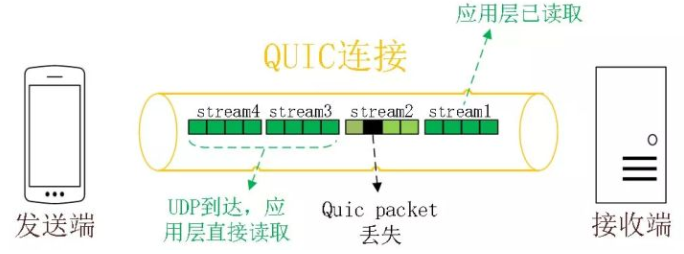
另外 QUIC 在移动端的表现也会比 TCP 好。因为 TCP 是基于 IP 和端口去识别连接的,这种方式在多变的移动端网络环境下是很脆弱的。但是 QUIC
是通过 ID 的方式去识别一个连接,不管你网络环境如何变化,只要 ID 不变,就能迅速重连上。
加密认证的报文
TCP
协议头部没有经过任何加密和认证,所以在传输过程中很容易被中间网络设备篡改,注入和窃听。比如修改序列号、滑动窗口。这些行为有可能是出于性能优化,也有可能是主动攻击。
但是 QUIC 的 packet 可以说是武装到了牙齿。除了个别报文比如 PUBLIC_RESET 和 CHLO,所有报文头部都是经过认证的,报文 Body
都是经过加密的。
这样只要对 QUIC 报文任何修改,接收端都能够及时发现,有效地降低了安全风险。
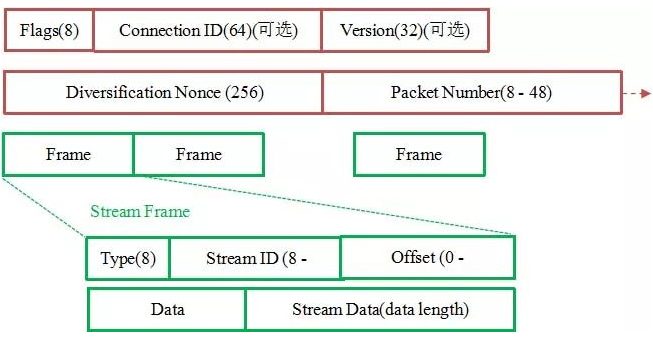
如上图所示,红色部分是 Stream Frame 的报文头部,有认证。绿色部分是报文内容,全部经过加密。
向前纠错机制
QUIC 协议有一个非常独特的特性,称为向前纠错 (Forward Error
Correction,FEC),每个数据包除了它本身的内容之外,还包括了部分其他数据包的数据,因此少量的丢包可以通过其他包的冗余数据直接组装而无需重传。向前纠错牺牲了每个数据包可以发送数据的上限,但是减少了因为丢包导致的数据重传,因为数据重传将会消耗更多的时间(包括确认数据包丢失、请求重传、等待新数据包等步骤的时间消耗)
假如说这次我要发送三个包,那么协议会算出这三个包的异或值并单独发出一个校验包,也就是总共发出了四个包。当出现其中的非校验包丢包的情况时,可以通过另外三个包计算出丢失的数据包的内容。
当然这种技术只能使用在丢失一个包的情况下,如果出现丢失多个包就不能使用纠错机制了,只能使用重传的方式了 。