ES索引生命周期管理(ILM)
ES的最佳实践
首先我们先来看下ES的最佳实践,这里列出了最核心的两点,分片大小的控制和分片数的设定
1. 单分片控制在50G以内(推荐日志场景在30G以内,搜索场景在10G以内)
分片大小为什么要控制呢?如果分片太大,我们在做数据迁移,reblance或者recovery的时候效率会特别低,影响集群的稳定性,同时分片太小了也不行,分片太小会导致同样数据量的情况下,集群的分片数会更多,ES的分片数越多,其实分片管理的效率会越低也会影响ES整体性能。
2. 索引的分片数位数据节点的倍数
比如有3个数据节点,那最好的分片数应该是3、6、9等等
如果能做到以上两点,整个集群的稳定性还是有一定保障的。但其实以上这两点是很难同时做到的,这中间有个矛盾就是索引分片数没办法修改,但是一般情况下数据量都是不断增长的,最总就会导致单个分片的大小超过最佳实践的推荐值。
那要如何解决索引分片数无法修改和数据持续增长的矛盾?
理想实现
那我们看下分布式系统中有没有这种比较理想的实现方式。
这边先举个例子,这里给出了一个有三个节点的数据集群,其中包含了3个shard
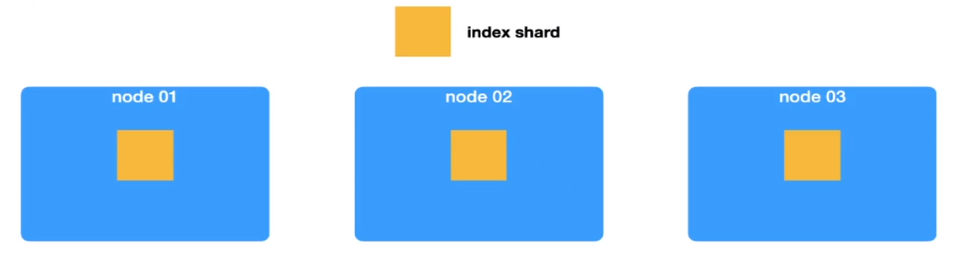
数据持续增长…
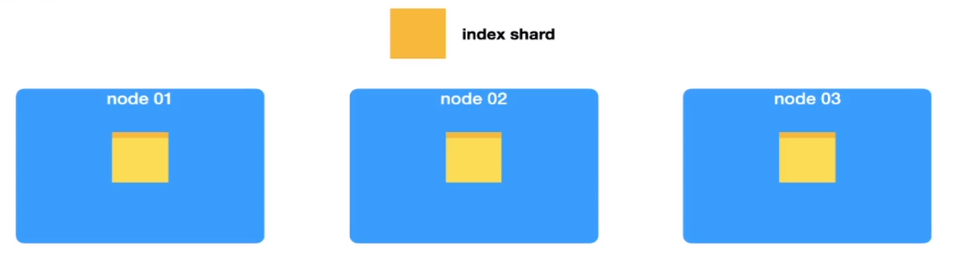
每个分片中的数据在不断增加,即将超过30G,这时候要怎么办呢?
方式一 分裂
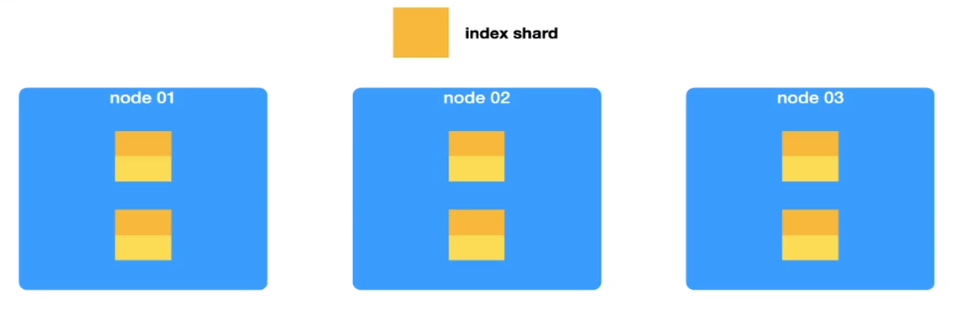
先把分片一分为二,再把数据平分,这样每个分片中就只存了一半的数据。如果数据不断增长,又满了,那就再次分裂。
方式二 新增
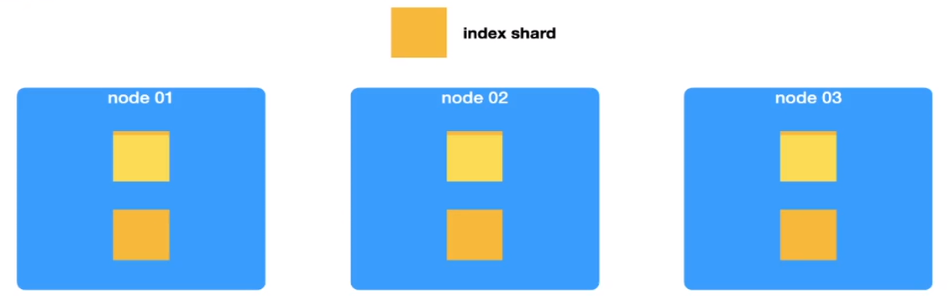
当数据满的时候,通过新增分片的方式来存储新的数据。ES中使用的方式就是这种新增的方式。
为什么ES没有使用方式一种的分裂方式呢?主要是因为数据的路由规则问题,ES用的是hash路由的方式来确定数据在哪个分片上,如果使用分裂的方式,每次分裂就需要重新对一半数据做reindex。(当然目前的es版本支持了split这种api,但实际上使用的并不多,因为性能较差)
理想实现 rollover
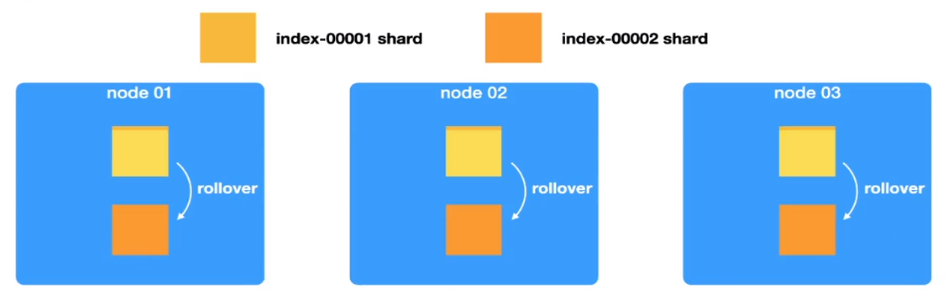
ES种新增的过程叫rollover,就是旧的索引(index-00001)满了之后会创建一个新的索引(index-00002),但从整体上来讲,他们对于用户来讲属于同一个索引,index-00001和index-00002被同一个逻辑索引或者叫别名(alias)纳管。程序使用的时候是通过别名来进行读写,rollover和alias是同时使用的。如果index-00002也满了,就会继续滚动,创建index-00003,同时被别名纳管。
这样就实现了shard随着数据的不断增长,自身也在不断增加,同时确保每个分片的数据量保持在推荐的范围内。
理想实现 migration
那实际生产中可能还有一中场景,就是随着时间的一部分数据查询频率会降低,数据价值也会降低,这时候如果如果可以把数据迁移到低配的机器上可以大大节省成本。
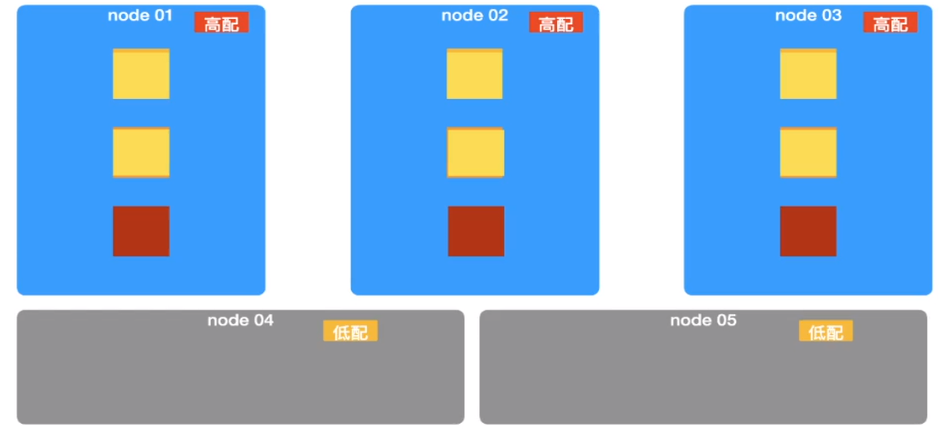
迁移
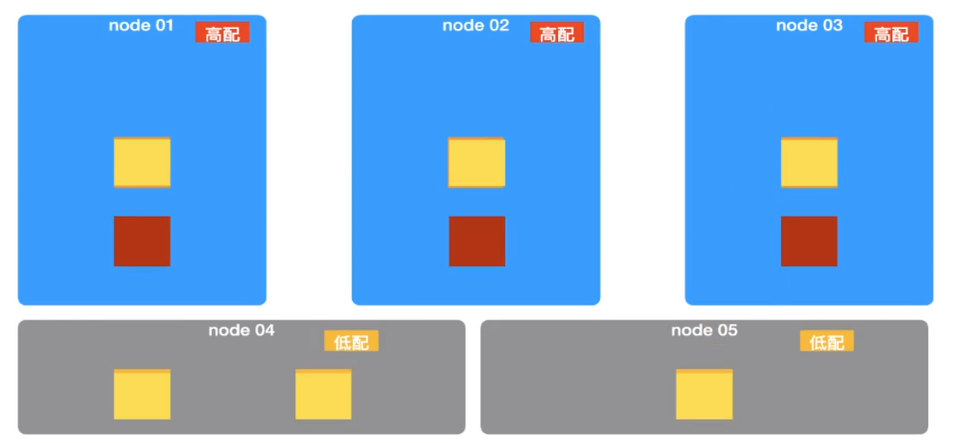
这样就可以更合理使用硬件资源,提升硬件使用效率。
再回头看最佳实践,单分片大小限制和分片数不可修改的问题就完美解决了。我们只需要根据业务情况来确定滚动周期以及数据每日增量即可确定分片数以及单分片大小,系统会根据配置自动滚动,生成新的索引。
ES的索引生命周期
索引的生命周期可以归纳为下面四个阶段
Hot阶段读写频繁,使用高配服务器,Warm、Cold使用低配机器即可满足
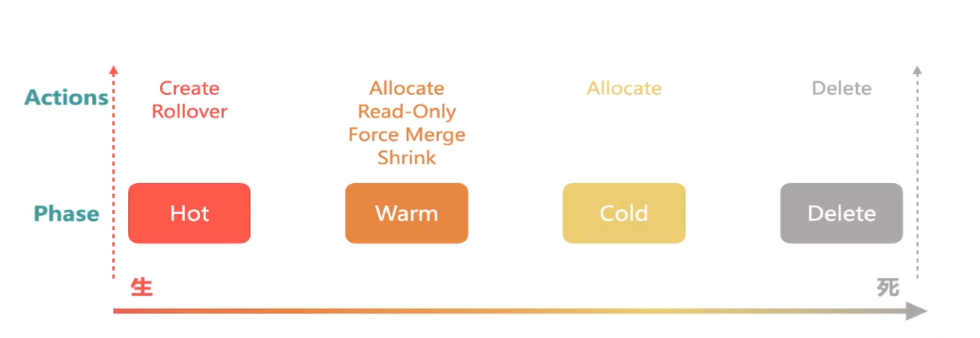
我们只需要搞清楚每个阶段做了生命操作即可
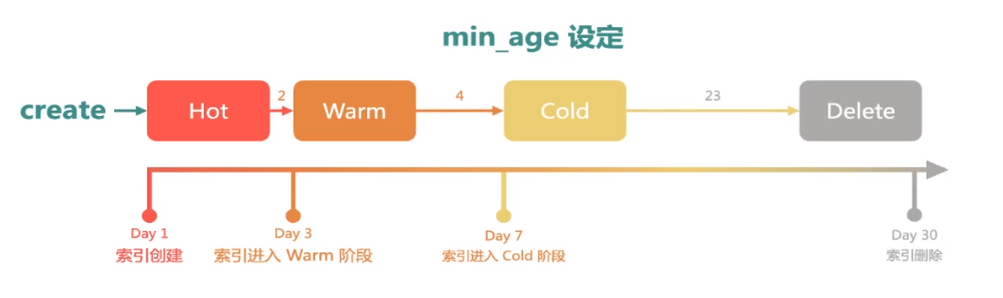
索引一单创建肯定是进入到Hot阶段,我们可以指定一个min_age,那两天之后就会进入到Warm阶段,然后再设置4天之后进入Cold阶段,以及23天后删除。
Hot Phase
Create
Index Template
Rollover
Index Alias
在索引文档数、大小、时间打到一定条件后,创建索引
控制Shard大小
Warm Phase
Allocate
Node Attribute
Index Shard Allocation
index.routing.allocation.require.*
Read-Only
index.blocks.read_only:true
Fource Merge
Shrink
Cold Phase
Allocate
Node Attribute
Index Shard Allocation
index.routing.allocation.require.*
Delete Phase
Delete
实战
创建rollover策略
如下策略的含义为:当索引的大小达到1000GB,索引创建超过1天时,自动进行滚 动;索引创建7天后,关闭数据副本;索引创建30天后,删除该索引。
策略可以根据具体业务场景进行配置。
1 | PUT _opendistro/_ism/policies/rollover_workflow |
创建好Rollover策略之后,可以通过如下命令查询策略详情:
1 | GET _opendistro/_ism/policies/rollover_workflow |
新建索引模板
如下模板的含义为:对于所有test开头的索引,其自动关联上面创建的rollover策略, 并且rollover时使用log_alias作为别名。 模板可以结合具体业务场景进行调整,比如:number_of_shards、refresh_interval, 以及mapping里面的参数等。
1 | PUT _template/template_test |
创建好索引模板之后,可以通过如下命令查询模板详情:
1 | GET _template/template_test |
创建第一个索引
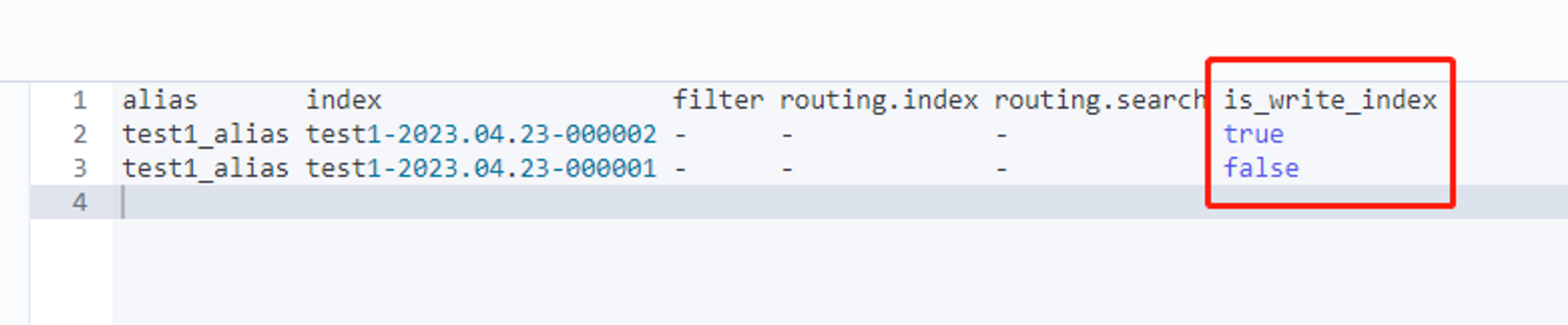
第一个索引要指定aliases,并且需要配置is_write_index为true。
如下索引是<test-{now/d}-000001>的URL编码,其创建时默认会带上当天的时间,比
如假设今天为2022.6.22,那么创建出来的索引名称为:test-2022.06.02-000001。
这里必须用urlencode,不然报错
1 | PUT %3Ctest-%7Bnow%2Fd%7D-000001%3E |
写入或查询数据
写入数据或查询数据时均使用别名log_alias,其中写入时log_alias始终指向最后一个 索引:
1 | POST log_alias/_bulk |
写入数据或查询数据时均使用别名log_alias,其中查询时log_alias指向所有的历史索引:
1 | GET log_alias/_search |
查询别名关联的索引情况:
1 | GET _cat/aliases?v |
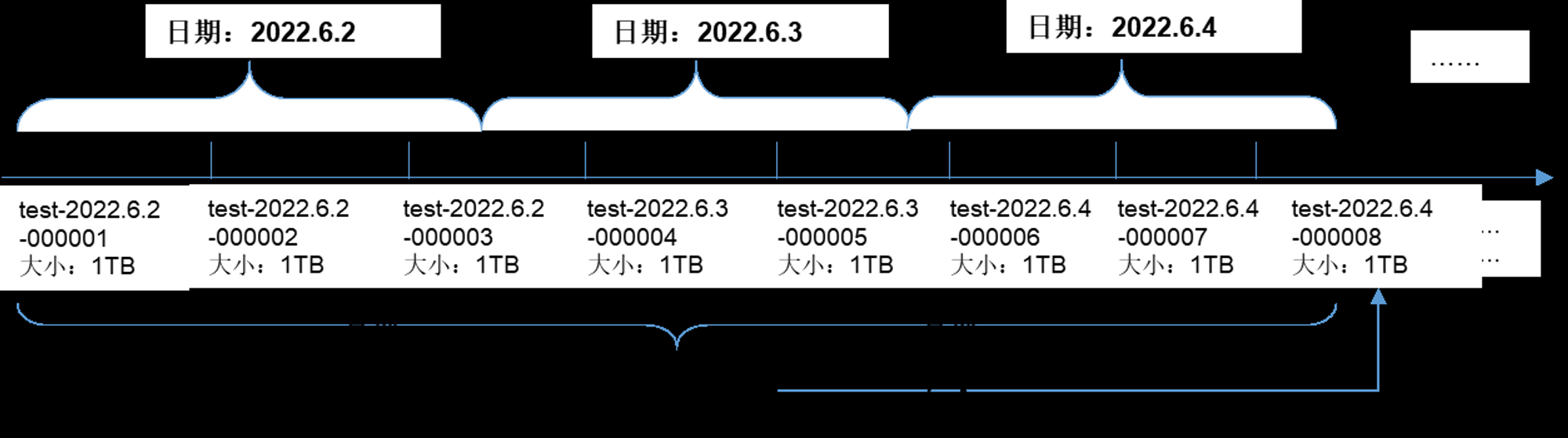
假设某个索引,其每天约产生2.4TB的数据,那么其数据在ES中的组织形态如下,其中索引别名 log-alias。 查询时指向所有test开头的索引,写入时指向最新的索引。
数据更新的问题
在实际开发测试中发现,历史数据使用索引别名更新的时候会存在问题。
假设历史A索引中存在一条x数据,当前索引为B索引
当再次更新这个x数据的时候,不会更新A索引中的这条数据,而是会插入到B索引中,此时再去查询x数据就会查询到两条。
原因:Rollover策略实现自动滚动索引后,历史索引的is_write_index属性会被设置为false,当通过索引别名来PUT数据时,只会从当前索引中判断是同存在相同数据。由于数据存在历史索引中,所以会在新索引中创建记录
解决方法:更新数据时先查询当前数据所在的索引,更新时带上索引
总结
通过ES的索引生命周期管理,我们可以根据业务需求,设置分片数与滚动策略,不用担心索引分片数不够,或者分片容量太大的问题。合理使用分片策略可以满足大部分订单类系统查询需求。