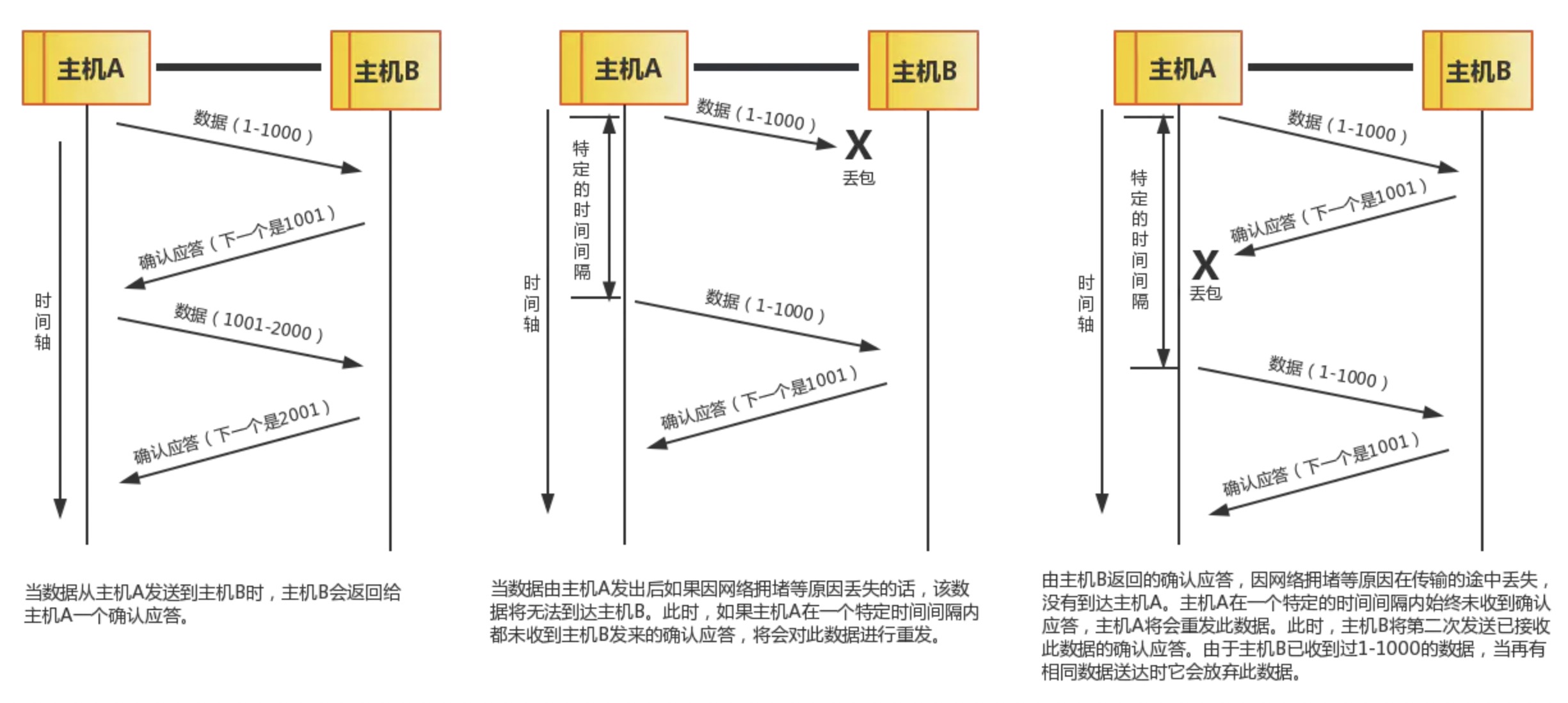
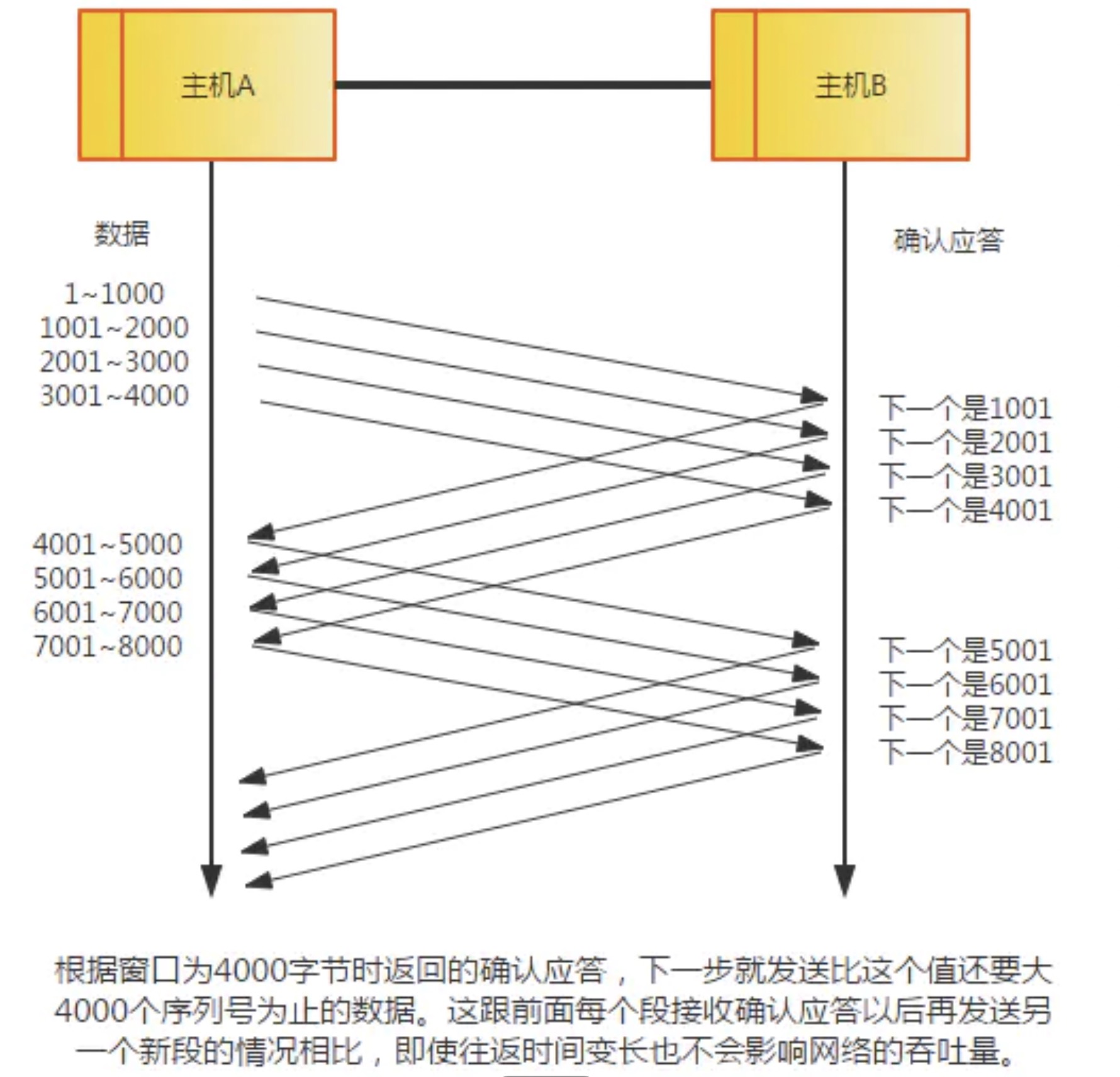
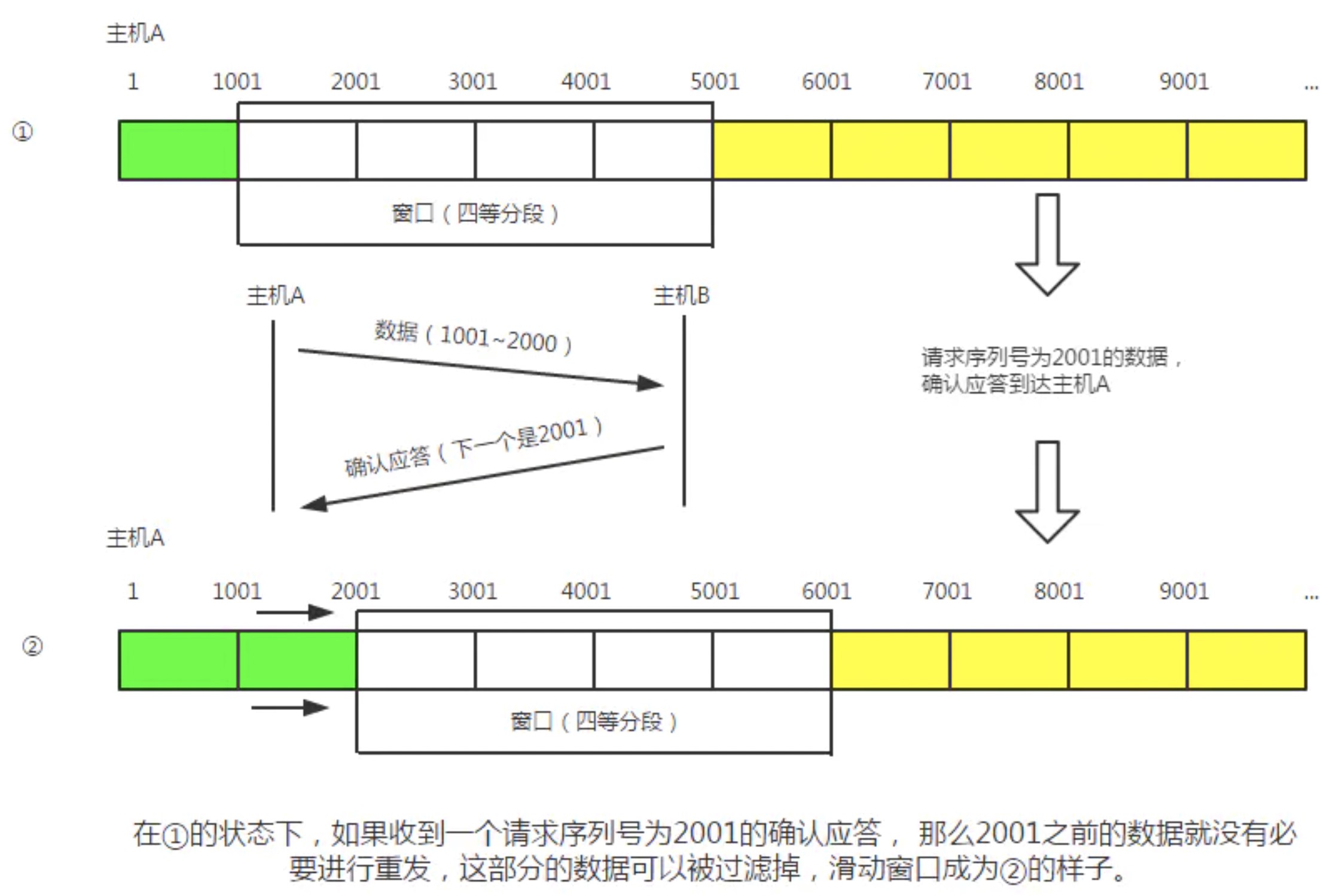
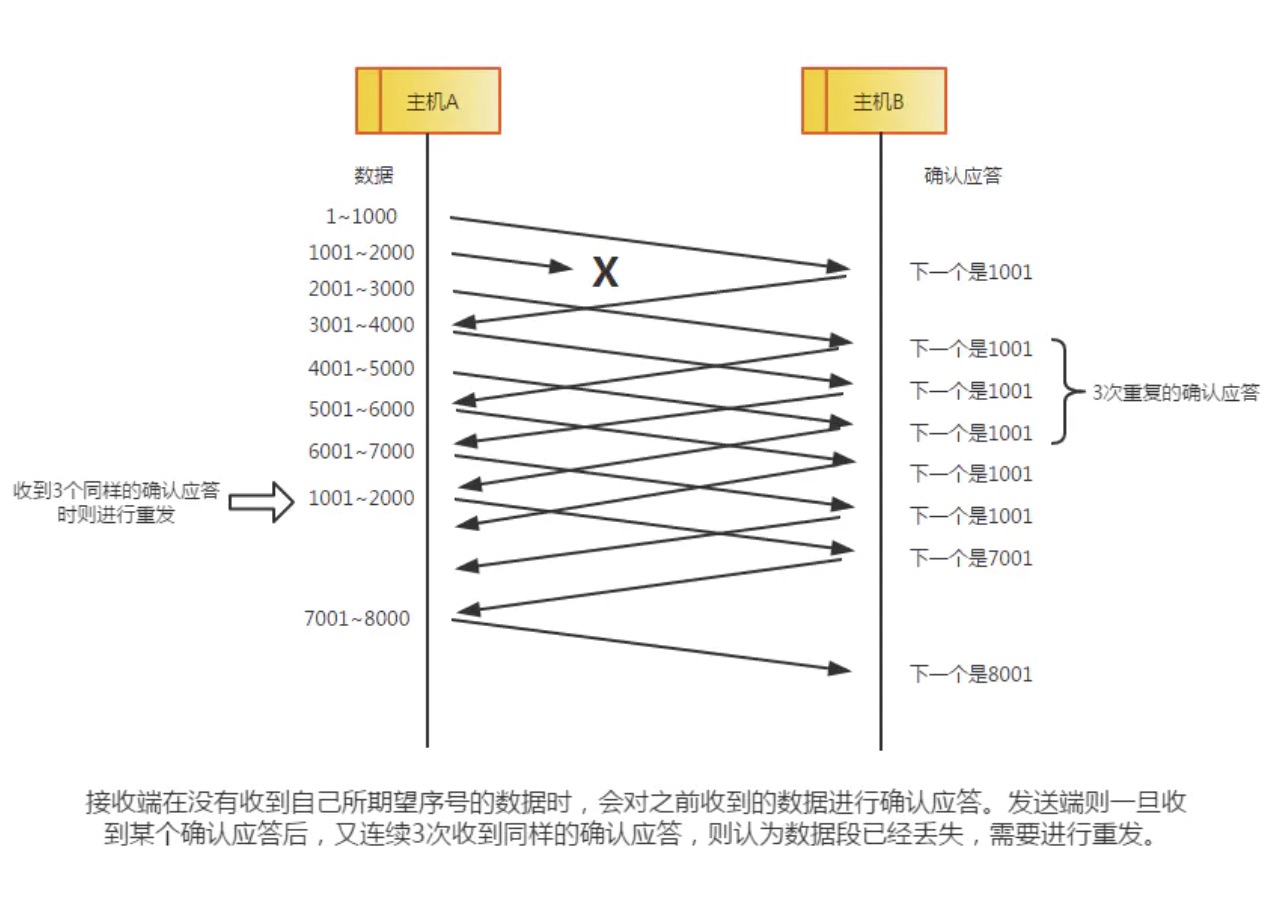
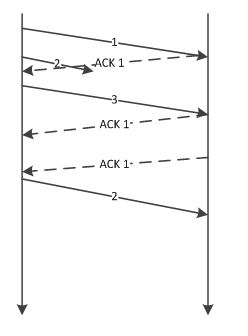
② 某个报文段丢失的情况。接收主机如果收到一个自己应该接收的序列号以外的数据时,会针对当前为止收到数据返回确认应答。如下图所示,当某一报文段丢失后,发送端会一直收到序号为1001的确认应答,因此,在窗口比较大,又出现报文段丢失的情况下,同一个序列号的确认应答将会被重复不断地返回。而发送端主机如果连续3次收到同一个确认应答,就会将其对应的数据进行重发。这种机制比之前提到的超时管理更加高效,因此也被称为高速重发控制。
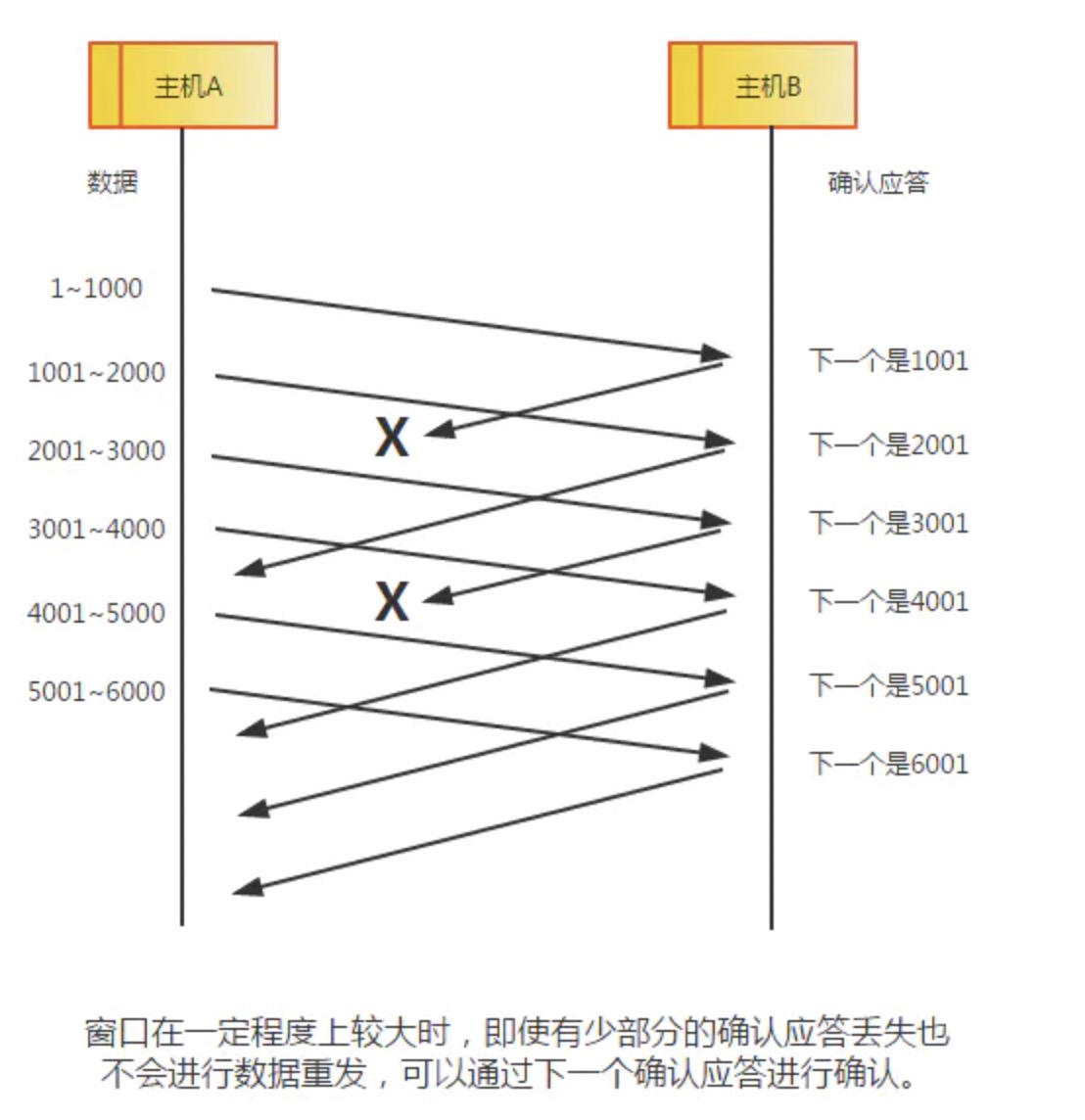
网络是一个很复杂的环境,如果有这么一种情况,网络发生了拥堵但是又那么的拥堵,这种情况的表现是什么呢?按照前面介绍过的滑动窗口,TCP不是one by one的发送数据包的,如果发送的数据包是1,2,3,1和3已经到,但是2没有到,由于拥堵在网络中丢失了,那么接收端会不断告诉发送端下一个需要的报文是2号报文,即使你后面的报文都到了,在2号报文没有收到的情况下,会一直发送对1号报文的ACK,表示需要的是2号报文。如果连续收到三个连续的ACK,就认为网络发生了拥堵。用语言描述有点绕,用图来表示就比较清晰。
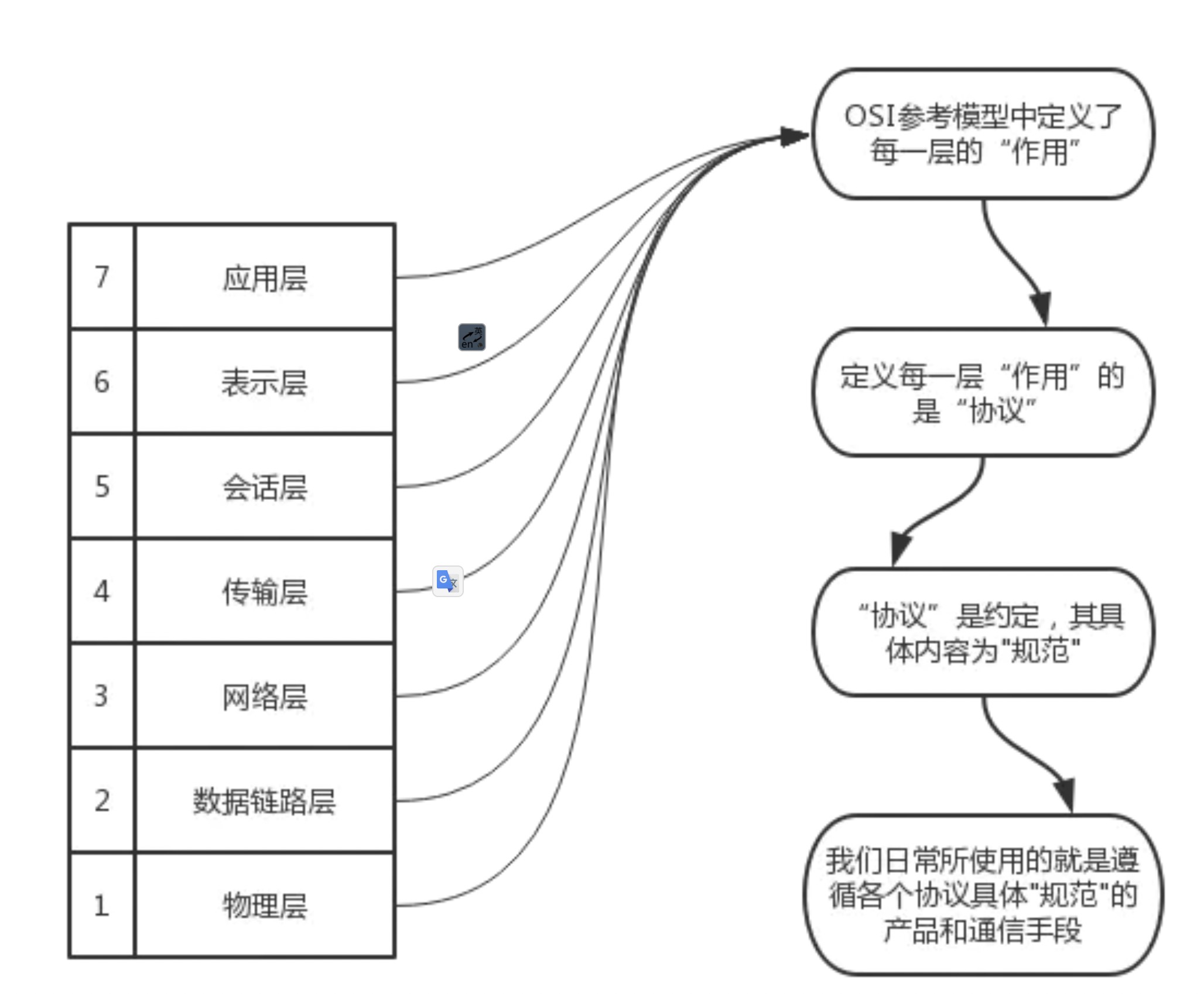
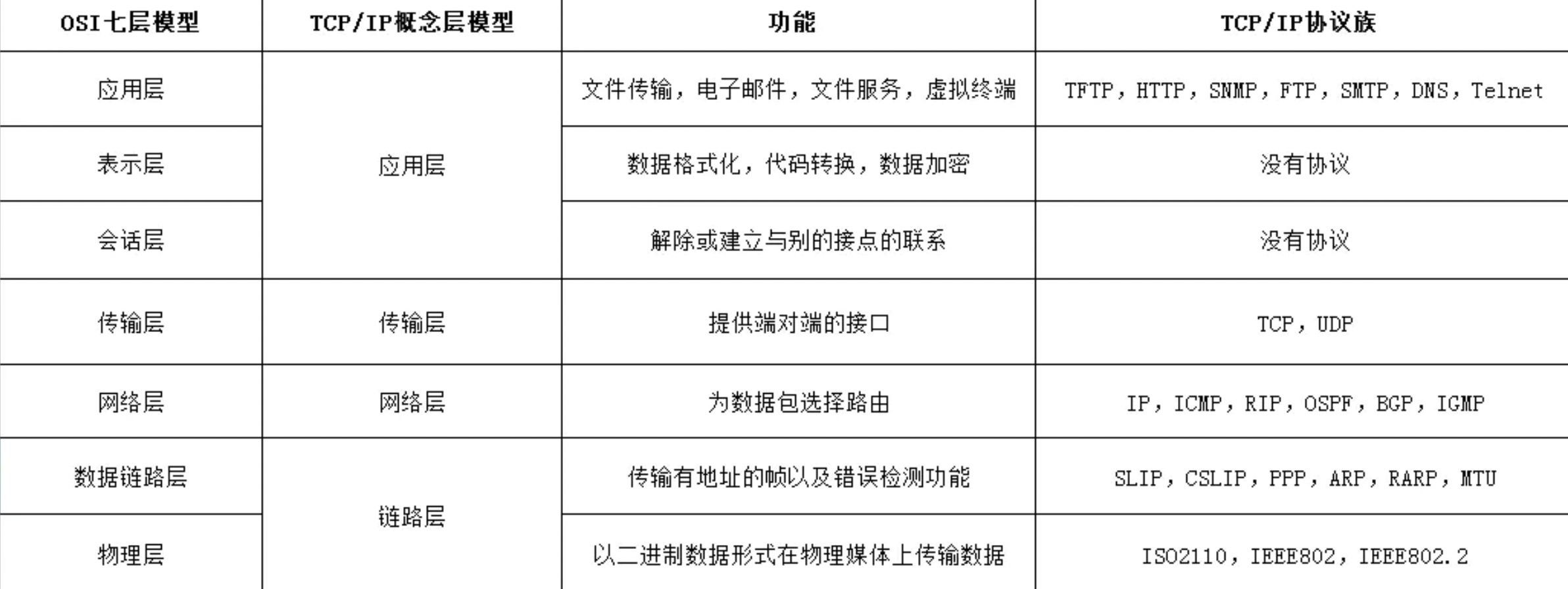
为了使不同体系结构的计算机网络都能互联,国际标准化组织 ISO 于1977年提出了一个试图使各种计算机在世界范围内互联成网的标准框架,即著名的开放系统互联基本参考模型 OSI/RM,简称为OSI。
OSI 的七层协议体系结构的概念清楚,理论也较完整,但它既复杂又不实用,TCP/IP 体系结构则不同,但它现在却得到了非常广泛的应用。TCP/IP 是一个四层体系结构,它包含应用层,运输层,网际层和网络接口层(用网际层这个名字是强调这一层是为了解决不同网络的互连问题),不过从实质上讲,TCP/IP 只有最上面的三层,因为最下面的网络接口层并没有什么具体内容,因此在学习计算机网络的原理时往往采用折中的办法,即综合 OSI 和 TCP/IP 的优点,采用一种只有五层协议的体系结构,这样既简洁又能将概念阐述清楚,有时为了方便,也可把最底下两层称为网络接口层。
有很多业务往往是读多写少的,比如系统配置的信息,除了在初始进行系统配置的时候需要写入数据,其他大部分时刻其他模块之后对系统信息只需要进行读取,又比如白名单,黑名单等配置,只需要读取名单配置然后检测当前用户是否在该配置范围以内。类似的还有很多业务场景,它们都是属于读多写少的场景。如果在这种情况用到上述的方法,使用 Vector,Collections 转换的这些方式是不合理的,因为尽管多个读线程从同一个数据容器中读取数据,但是读线程对数据容器的数据并不会发生发生修改。很自然而然的我们会联想到 ReenTrantReadWriteLock,通过读写分离的思想,使得读读之间不会阻塞,无疑如果一个 list 能够做到被多个读线程读取的话,性能会大大提升不少。但是,如果仅仅是将 list 通过读写锁(ReentrantReadWriteLock)进行再一次封装的话,由于读写锁的特性,当写锁被写线程获取后,读写线程都会被阻塞。如果仅仅使用读写锁对 list 进行封装的话,这里仍然存在读线程在读数据的时候被阻塞的情况,如果想 list 的读效率更高的话,这里就是我们的突破口,如果我们保证读线程无论什么时候都不被阻塞,效率岂不是会更高?
/** The array, accessed only via getArray/setArray. */ private transient volatile Object[] array;
并且该数组引用是被 volatile 修饰,注意这里仅仅是修饰的是数组引用,其中另有玄机,稍后揭晓。关于 volatile 很重要的一条性质是它能够够保证可见性。对 list 来说,我们自然而然最关心的就是读写的时候,分别为 get 和 add 方法的实现。
get方法
get 方法的源码为:
1 2 3 4 5 6 7 8 9 10 11 12 13
public E get(int index) { return get(getArray(), index); } /** * Gets the array. Non-private so as to also be accessible * from CopyOnWriteArraySet class. */ final Object[] getArray() { return array; } private E get(Object[] a, int index) { return (E) a[index]; }
可以看出来 get 方法实现非常简单,几乎就是一个“单线程”程序,没有对多线程添加任何的线程安全控制,也没有加锁也没有 CAS 操作等等,原因是,所有的读线程只是会读取数据容器中的数据,并不会进行修改。
add方法
再来看下如何进行添加数据的?add 方法的源码为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
public boolean add(E e) { final ReentrantLock lock = this.lock; //1. 使用Lock,保证写线程在同一时刻只有一个 lock.lock(); try { //2. 获取旧数组引用 Object[] elements = getArray(); int len = elements.length; //3. 创建新的数组,并将旧数组的数据复制到新数组中 Object[] newElements = Arrays.copyOf(elements, len + 1); //4. 往新数组中添加新的数据 newElements[len] = e; //5. 将旧数组引用指向新的数组 setArray(newElements); return true; } finally { lock.unlock(); } }
在队列进行出队入队的时候免不了对节点需要进行操作,在多线程就很容易出现线程安全的问题。可以看出在处理器指令集能够支持CMPXCHG指令后,在 java 源码中涉及到并发处理都会使用 CAS 操作(关于 CAS 操作可以看这篇文章的第 3.1 节),那么在 ConcurrentLinkedQueue 对 Node 的 CAS 操作有这样几个:
public boolean offer(E e) { //e为null则抛出空指针异常 checkNotNull(e); final Node<E> newNode = new Node<E>(e); //从尾节点插入 for (Node<E> t = tail, p = t;;) {
Node<E> q = p.next;
//如果q=null说明p是尾节点则插入 if (q == null) {
//cas插入(1) if (p.casNext(null, newNode)) { //cas成功说明新增节点已经被放入链表,然后设置当前尾节点(包含head,1,3,5.。。个节点为尾节点) if (p != t) // hop two nodes at a time casTail(t, newNode); // Failure is OK. return true; } // Lost CAS race to another thread; re-read next } else if (p == q)//(2) //多线程操作时候,由于poll时候会把老的head变为自引用,然后head的next变为新head,所以这里需要 //重新找新的head,因为新的head后面的节点才是激活的节点 //或者是新的集合,p节点==p节点的next节点,正准备第一次添加节点,所以返回head节点 p = (t != (t = tail)) ? t : head; else // 寻找尾节点(3) p = (p != t && t != (t = tail)) ? t : q; } }
/** * Returns a power of two table size for the given desired capacity. * See Hackers Delight, sec 3.2 */ private static final int tableSizeFor(int c) { int n = c - 1; n |= n >>> 1; n |= n >>> 2; n |= n >>> 4; n |= n >>> 8; n |= n >>> 16; return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1; }
public int size() { long n = sumCount(); return ((n < 0L) ? 0 : (n > (long)Integer.MAX_VALUE) ? Integer.MAX_VALUE : (int)n); } final long sumCount() { CounterCell[] as = counterCells; CounterCell a; long sum = baseCount; if (as != null) { for (int i = 0; i < as.length; ++i) { //遍历,所有counter求和 if ((a = as[i]) != null) sum += a.value; } } return sum; }
public class MyRunnable implements Runnable { @Override public void run() { System.out.println(Thread.currentThread().getName() + " run()方法执行中..."); } }
public class SingleThreadExecutorTest { public static void main(String[] args) { ExecutorService executorService = Executors.newSingleThreadExecutor(); MyRunnable runnableTest = new MyRunnable(); for (int i = 0; i < 5; i++) { executorService.execute(runnableTest); } System.out.println("线程任务开始执行"); executorService.shutdown(); } }
执行结果
1 2 3 4 5 6
线程任务开始执行 pool-1-thread-1 is running... pool-1-thread-1 is running... pool-1-thread-1 is running... pool-1-thread-1 is running... pool-1-thread-1 is running...
runnable 和 callable 的区别
相同点
都是接口
都可以编写多线程程序
都采用Thread.start()启动线程
主要区别
Runnable 接口 run 方法无返回值;Callable 接口 call 方法有返回值,是个泛型,和Future、FutureTask配合可以用来获取异步执行的结果
Runnable 接口 run 方法只能抛出运行时异常,且无法捕获处理;Callable 接口 call 方法允许抛出异常,可以获取异常信息
private static final ThreadFactory NAMED_THREAD_FACTORY = new ThreadFactoryBuilder() .setNameFormat("thread-name-%d").build(); private static final ExecutorService THREAD_POOL = new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<>(), NAMED_THREAD_FACTORY);
public static ExecutorService newFixedThreadPool(int nThreads) { return new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()); }
newSingleThreadExecutor
单任务队列的线程池,最大线程数和核心线程数都是1,无界队列,所有的任务都按照顺序进行执行;
1 2 3 4 5 6
public static ExecutorService newSingleThreadExecutor() { return new FinalizableDelegatedExecutorService (new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>())); }
ScheduledThreadPool
支持定时周期性执行任务的线程池;
1 2 3
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) { return new ScheduledThreadPoolExecutor(corePoolSize); }
public static ExecutorService newCachedThreadPool() { return new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>()); }
源码分析
任务的提交
submit方法源码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
public Future<?> submit(Runnable task) { if (task == null) throw new NullPointerException(); RunnableFuture<Void> ftask = newTaskFor(task, null); execute(ftask); return ftask; } public <T> Future<T> submit(Callable<T> task) { if (task == null) throw new NullPointerException(); RunnableFuture<T> ftask = newTaskFor(task); execute(ftask); return ftask; } public <T> Future<T> submit(Runnable task, T result) { if (task == null) throw new NullPointerException(); RunnableFuture<T> ftask = newTaskFor(task, result); execute(ftask); return ftask; }
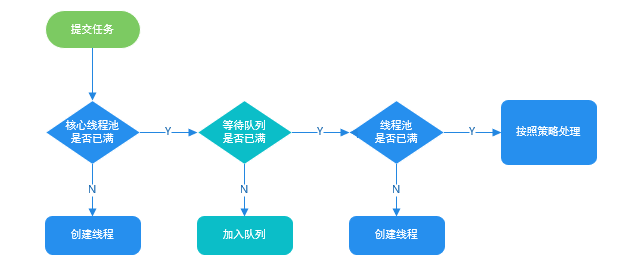
public void execute(Runnable command) { if (command == null) throw new NullPointerException(); int c = ctl.get(); if (workerCountOf(c) < corePoolSize) { if (addWorker(command, true)) return; c = ctl.get(); } if (isRunning(c) && workQueue.offer(command)) { int recheck = ctl.get(); if (! isRunning(recheck) && remove(command)) reject(command); else if (workerCountOf(recheck) == 0) addWorker(null, false); } else if (!addWorker(command, false)) reject(command); }