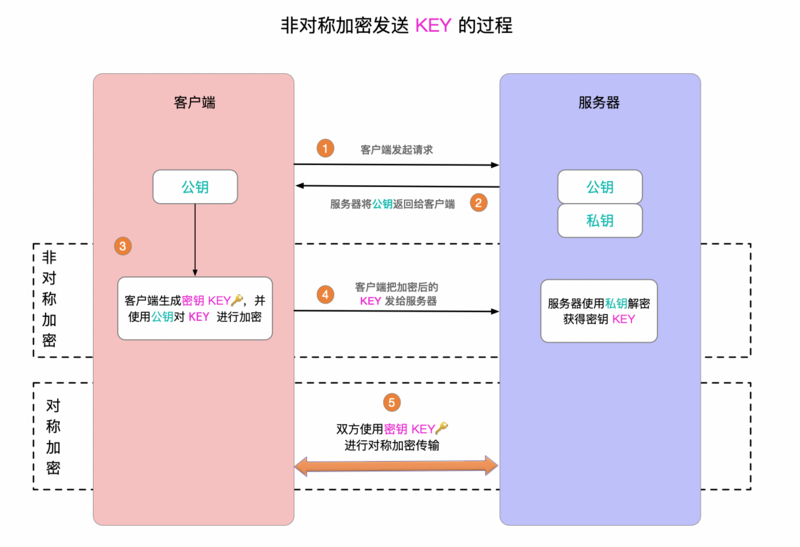
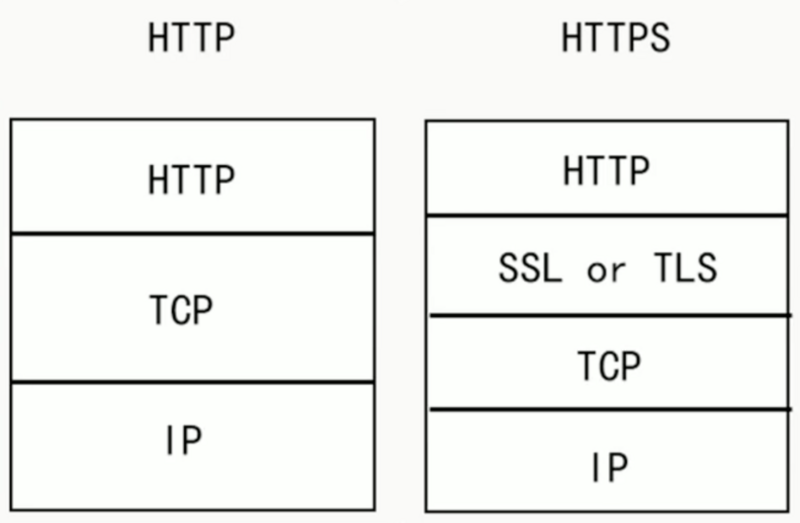
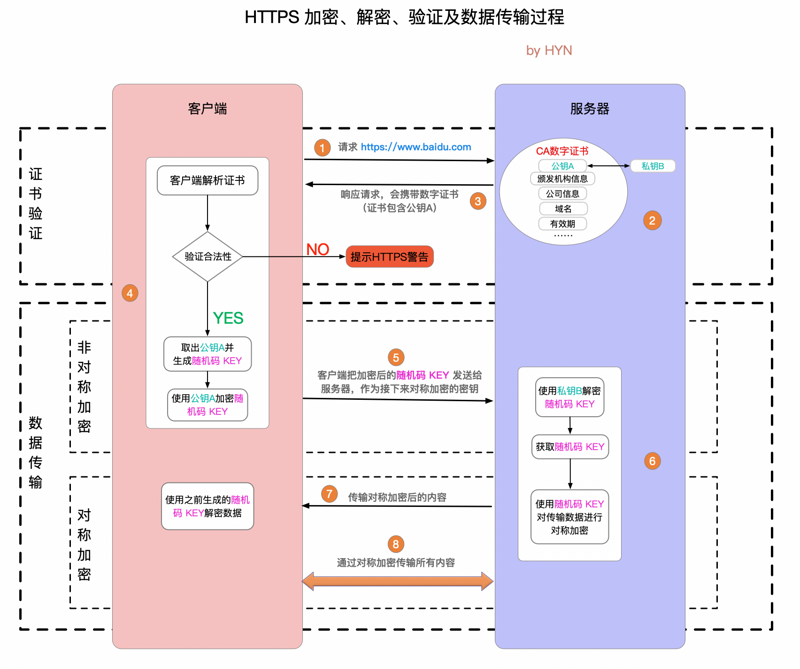
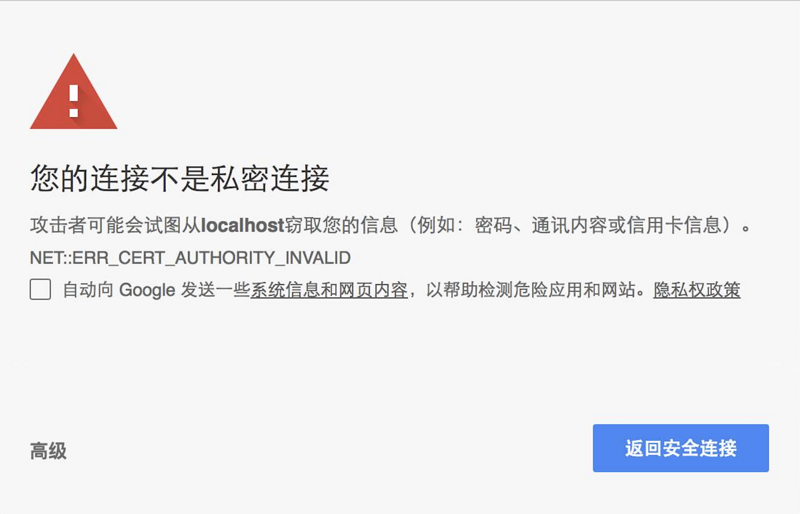
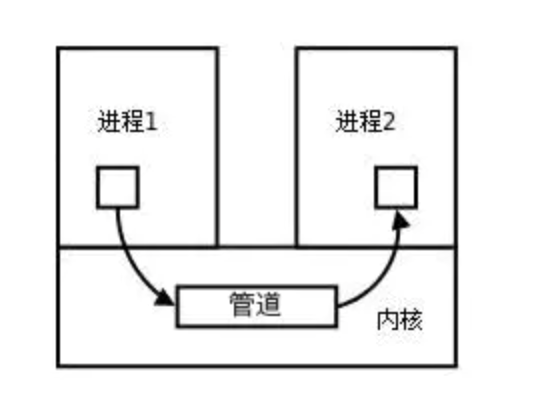
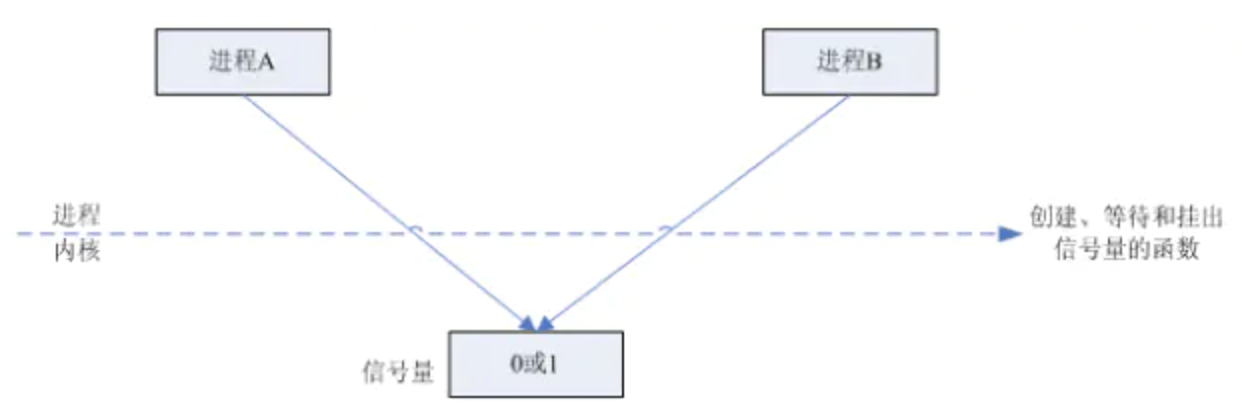
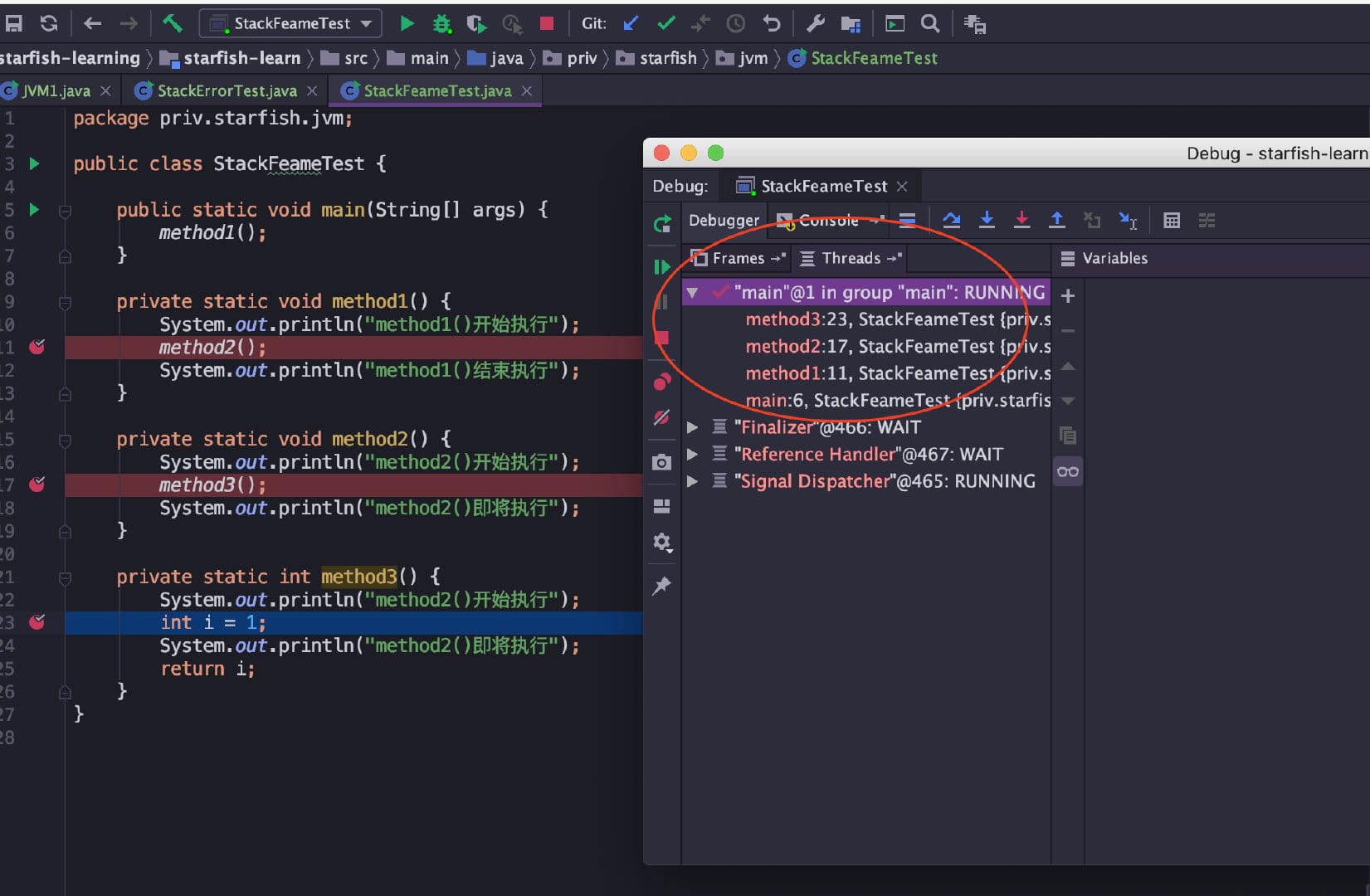
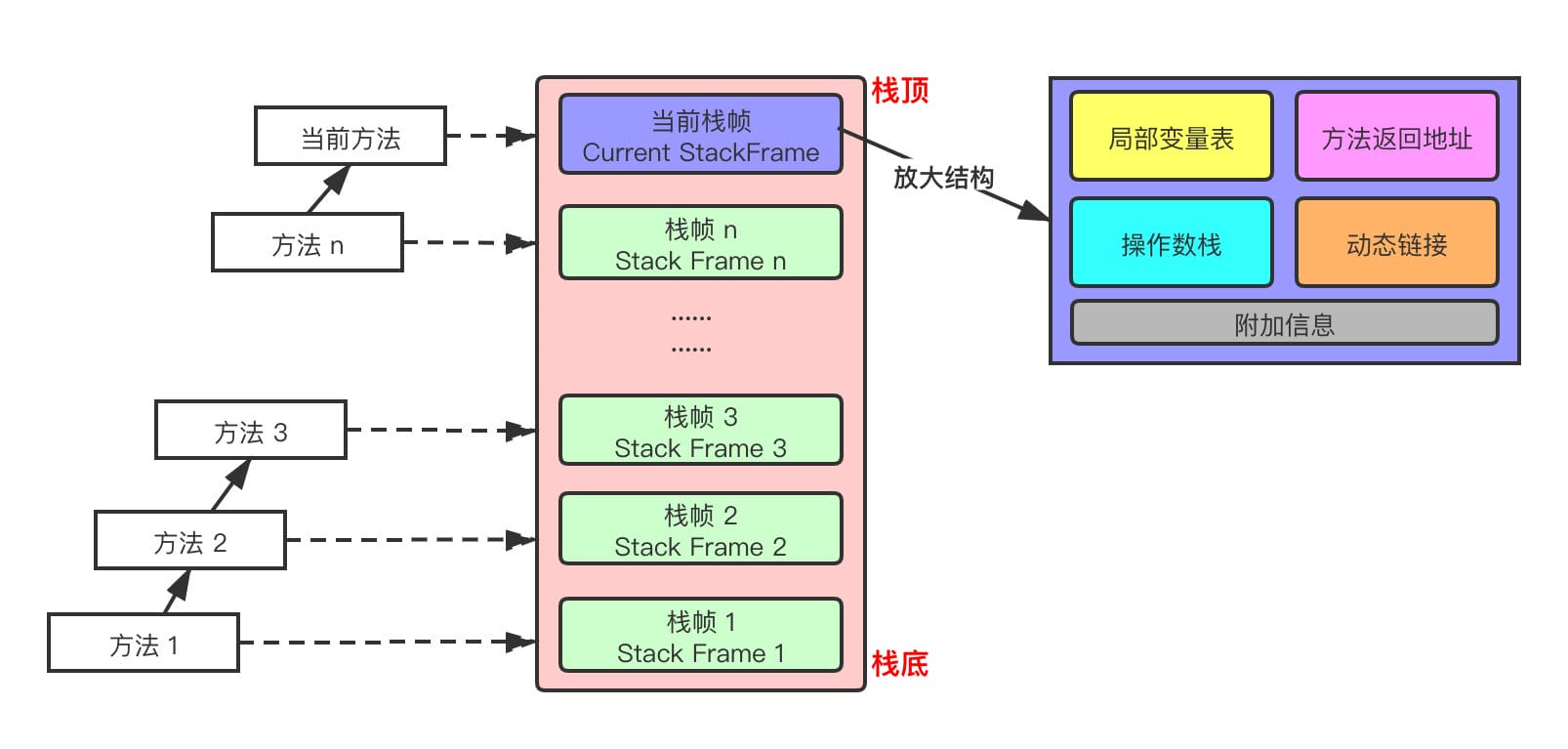
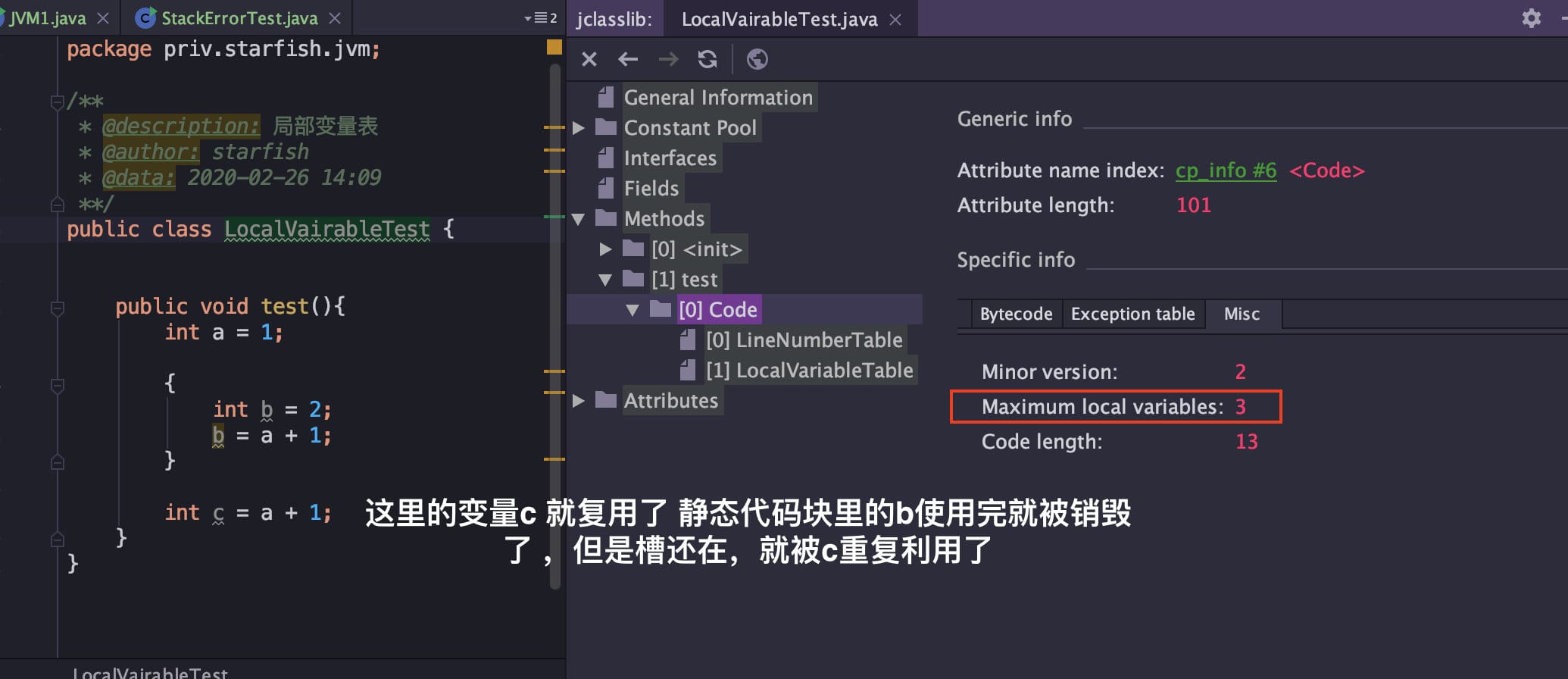
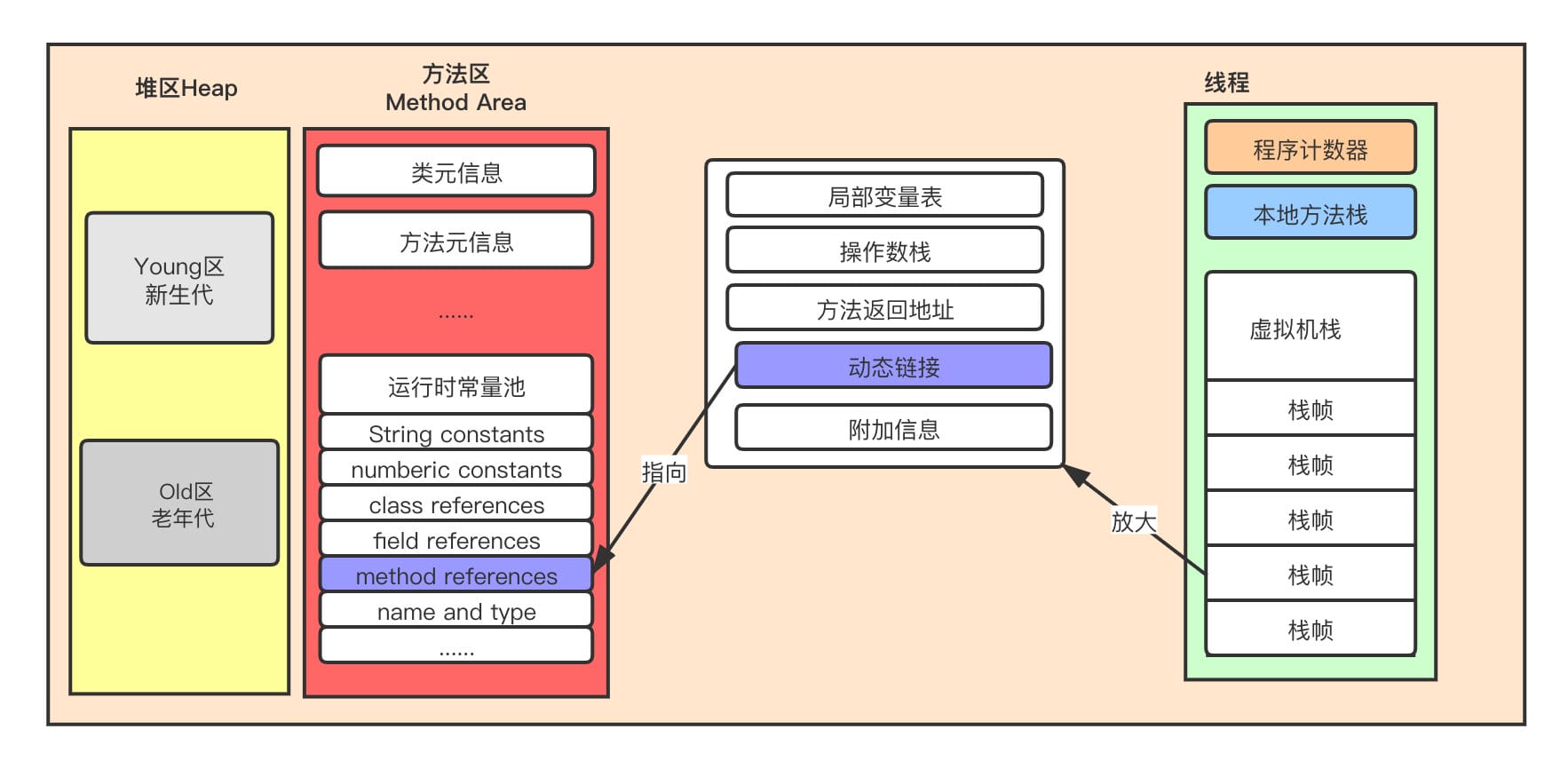
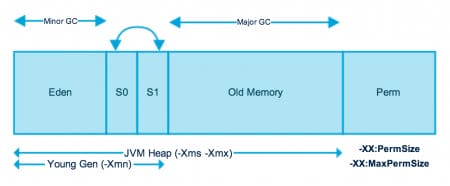
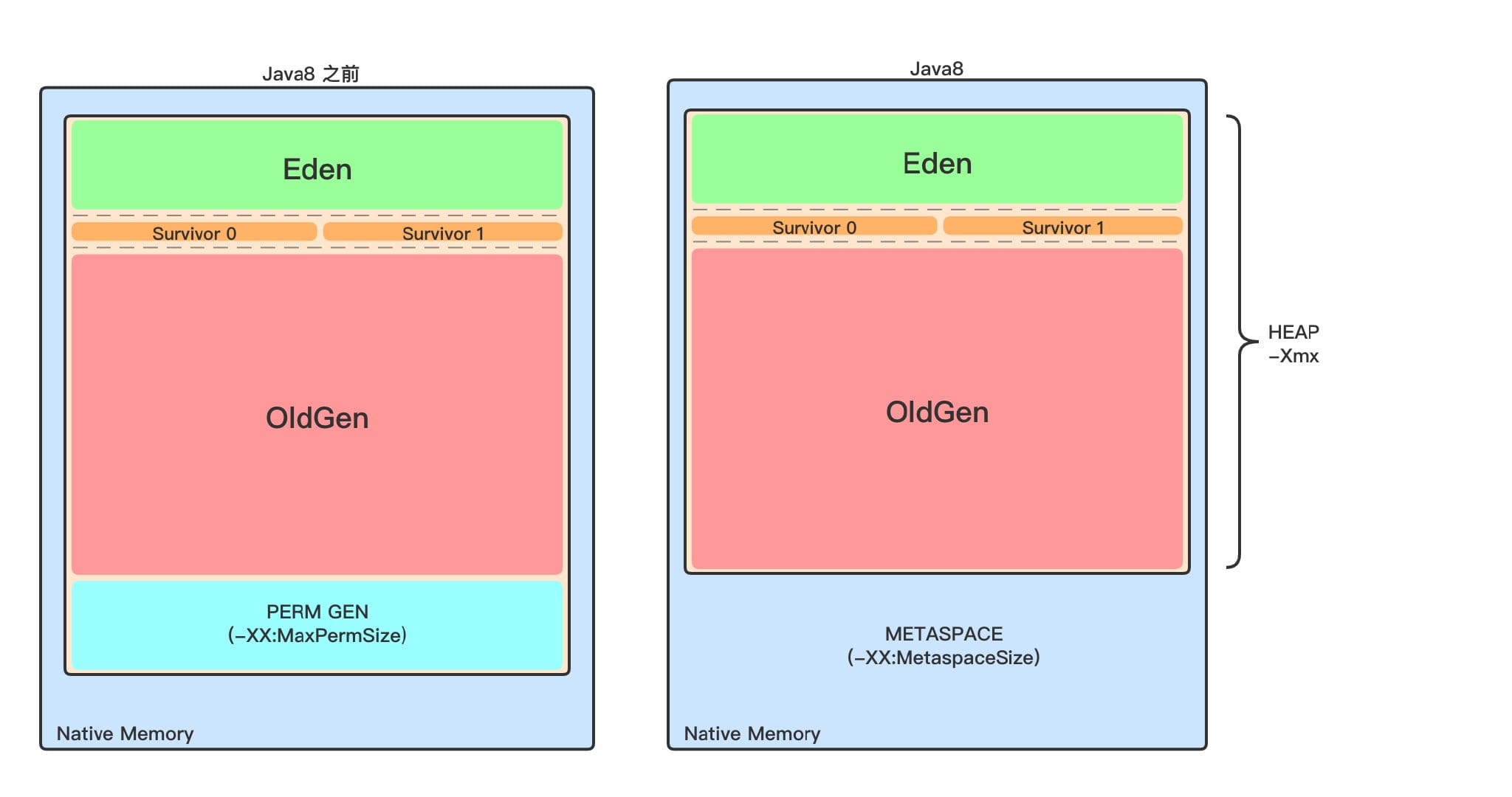
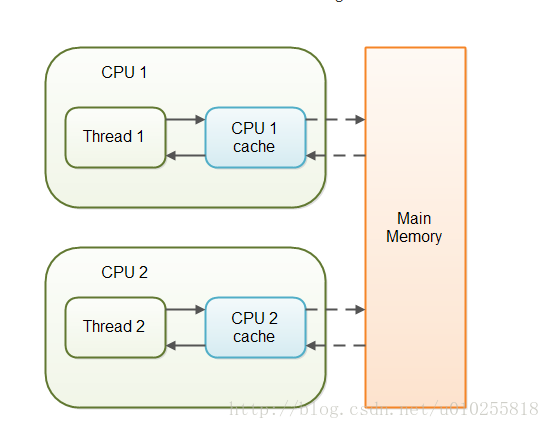
volatile
作用
保证内存可见性
基本概念
可见性是指线程之间的可见性,一个线程修改的状态对另一个线程是可见的。也就是一个线程修改的结果,另一个线程马上就能看到。
实现原理
当对非volatile变量进行读写的时候,每个线程先从主内存拷贝变量到CPU缓存中,如果计算机有多个CPU,每个线程可能在不同的CPU上被处理,这意味着每个线程可以拷贝到不同的CPU
cache中。
volatile变量不会被缓存在寄存器或者对其他处理器不可见的地方,保证了每次读写变量都从主内存中读,跳过CPU
cache这一步。当一个线程修改了这个变量的值,新值对于其他线程是立即得知的。
禁止指令重排序
基本概念
指令重排序是JVM为了优化指令、提高程序运行效率,在不影响单线程程序执行结果的前提下,尽可能地提高并行度。指令重排序包括编译器重排序和运行时重排序。
在JDK1.5之后,可以使用volatile变量禁止指令重排序。针对volatile修饰的变量,在读写操作指令前后会插入内存屏障,指令重排序时不能把后面的指令重排序到内存屏
示例说明:
double r = 2.1; //(1)
double pi = 3.14;//(2)
double area = pi*r*r;//(3)1234
虽然代码语句的定义顺序为1->2->3,但是计算顺序1->2->3与2->1->3对结果并无影响,所以编译时和运行时可以根据需要对1、2语句进行重排序。后面写文章分析一下JIT的问题,工作中同事提出了一个有意思的问题。。
指令重排序带来的问题
基于双重检验的单例模式(懒汉型)
public class Singleton3 {
private static Singleton3 instance = null;
private Singleton3() {}
public static Singleton3 getInstance() {
if (instance == null) {
synchronized(Singleton3.class) {
if (instance == null)
instance = new Singleton3();// 非原子操作
}
}
return instance;
}
}12345678910111213141516
instance= new Singleton()并不是一个原子操作,其实际上可以抽象为下面几条JVM指令:
memory =allocate(); //1:分配对象的内存空间
ctorInstance(memory); //2:初始化对象
instance =memory; //3:设置instance指向刚分配的内存地址123
上面操作2依赖于操作1,但是操作3并不依赖于操作2。所以JVM是可以针对它们进行指令的优化重排序的,经过重排序后如下:
memory =allocate(); //1:分配对象的内存空间
instance =memory; //3:instance指向刚分配的内存地址,此时对象还未初始化
ctorInstance(memory); //2:初始化对象123
指令重排之后,instance指向分配好的内存放在了前面,而这段内存的初始化被排在了后面。在线程A执行这段赋值语句,在初始化分配对象之前就已经将其赋值给instance引用,恰好另一个线程进入方法判断instance引用不为null,然后就将其返回使用,导致出错。
解决办法
用volatile关键字修饰instance变量,使得instance在读、写操作前后都会插入内存屏障,避免重排序。
public class Singleton3 {
private static volatile Singleton3 instance = null;
private Singleton3() {}
public static Singleton3 getInstance() {
if (instance == null) {
synchronized(Singleton3.class) {
if (instance == null)
instance = new Singleton3();
}
}
return instance;
}
volatile关键字提供内存屏障的方式来防止指令被重排,编译器在生成字节码文件时,会在指令序列中插入内存屏障来禁止特定类型的处理器重排序。
JVM内存屏障插入策略:
- 每个volatile写操作的前面插入一个StoreStore屏障;
- 在每个volatile写操作的后面插入一个StoreLoad屏障;
- 在每个volatile读操作的后面插入一个LoadLoad屏障;
- 在每个volatile读操作的后面插入一个LoadStore屏障。
适用场景
- volatile是 轻量级同步机制 。在访问volatile变量时不会执行加锁操作,因此也就不会使执行线程阻塞,是一种比synchronized关键字更轻量级的同步机制。
- volatile 无法同时保证内存可见性和原子性 。加锁机制既可以确保可见性又可以确保原子性,而volatile变量 只能确保可见性 。
- volatile不能修饰写入操作依赖当前值的变量。声明为volatile的简单变量如果当前值与该变量以前的值相关,那么volatile关键字不起作用,也就是说如下的表达式都不是原子操作:“count++”、“count = count+1”。
- 当要访问的变量已在synchronized代码块中,或者为常量时,没必要使用volatile;
- volatile屏蔽掉了JVM中必要的代码优化,所以在效率上比较低,因此一定在必要时才使用此关键字。
虽然volatile只能保证可见性不能保证原子性,但用volatile修饰long和double可以保证其操作原子性。
所以从Oracle Java Spec里面可以看到:
- 对于64位的long和double,如果没有被volatile修饰,那么对其操作可以不是原子的。在操作的时候,可以分成两步,每次对32位操作。
- 如果使用volatile修饰long和double,那么其读写都是原子操作
- 对于64位的引用地址的读写,都是原子操作
- 在实现JVM时,可以自由选择是否把读写long和double作为原子操作
- 推荐JVM实现为原子操作
synchronized
众所周知 synchronized 关键字是解决并发问题常用解决方案,有以下三种使用方式:
- 同步普通方法,锁的是当前对象。
- 同步静态方法,锁的是当前
Class 对象。
- 同步块,锁的是
() 中的对象。
实现原理
JVM 是通过进入、退出对象监视器( Monitor )来实现对方法、同步块的同步的。
具体实现是在编译之后在同步方法调用前加入一个 monitor.enter 指令,在退出方法和异常处插入 monitor.exit 的指令。
其本质就是对一个对象监视器( Monitor )进行获取,而这个获取过程具有排他性从而达到了同一时刻只能一个线程访问的目的。
而对于没有获取到锁的线程将会阻塞到方法入口处,直到获取锁的线程 monitor.exit 之后才能尝试继续获取锁。
锁优化
synchronized 很多都称之为重量锁,JDK1.6 中对 synchronized
进行了各种优化,为了能减少获取和释放锁带来的消耗引入了偏向锁和轻量锁。
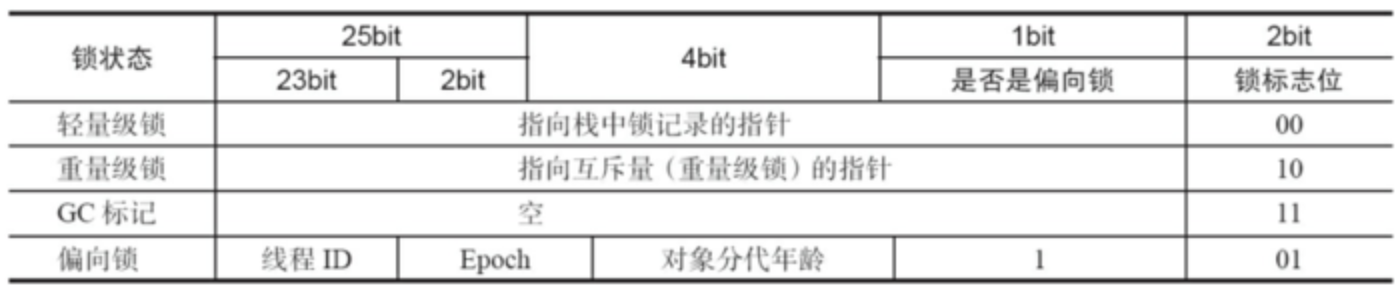
Java SE 1.6中,锁一共有4种状态,级别从低到高依次是: 无锁状态、偏向锁状态、轻量级锁状态和重量级锁状态
,这几个状态会随着竞争情况逐渐升级。 锁可以升级但不能降级
,意味着偏向锁升级成轻量级锁后不能降级成偏向锁。这种锁升级却不能降级的策略,目的是为了提高获得锁和释放锁的效率。对象的MarkWord变化为下图:
偏向锁
HotSpot的作者经过研究发现,大多数情况下,锁不仅不存在多线程竞争,而且总是由同一线程多次获得,为了让线程获得锁的代价更低而引入了偏向锁。
获取锁
当一个线程访问同步块并获取锁时,会在 对象头 和 栈帧中的锁记录
里存储锁偏向的线程ID,以后该线程在进入和退出同步块时不需要进行CAS操作来加锁和解锁,只需简单地测试一下对象头的Mark
Word里是否存储着指向当前线程的偏向锁。如果测试成功,表示线程已经获得了锁。如果测试失败,则需要再测试一下Mark
Word中偏向锁的标识是否设置成1(表示当前是偏向锁):如果没有设置,则使用CAS竞争锁;如果设置了,则尝试使用CAS将对象头的偏向锁指向当前线程
释放锁
偏向锁使用了一种 等到竞争出现才释放锁 的机制,所以当其他线程尝试竞争偏向锁时,持有偏向锁的线程才会释放锁。
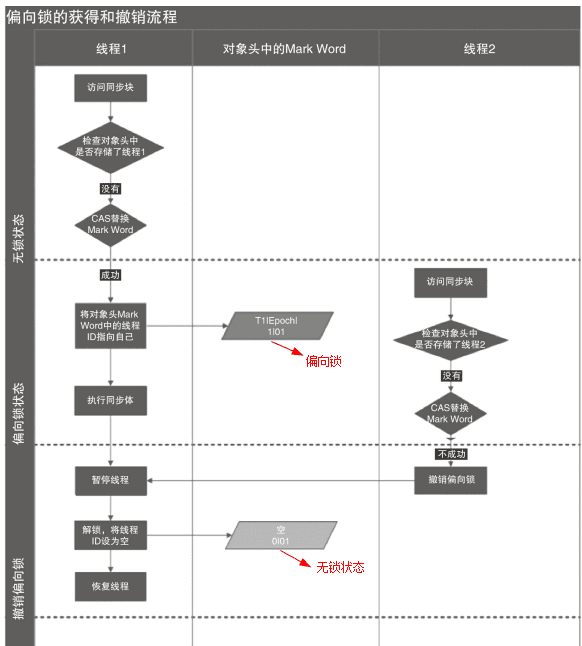
如图,偏向锁的撤销,需要等待 全局安全点
(在这个时间点上没有正在执行的字节码)。它会首先暂停拥有偏向锁的线程,然后检查持有偏向锁的线程是否活着,如果线程不处于活动状态,则将对象头设置成无锁状态;如果线程仍然活着,拥有偏向锁的栈会被执行,遍历偏向对象的锁记录,栈中的锁记录和对象头的Mark
Word 要么 重新偏向于其他线程, 要么 恢复到无锁或者标记对象不适合作为偏向锁,最后唤醒暂停的线程。
如果配置中关闭偏向锁,则直接进入轻量级锁
轻量级锁
当偏向锁出现锁竞争时,就会升级为轻量级锁。
加锁
线程在执行同步块之前,JVM会先在当前线程的栈桢中 创建用于存储锁记录的空间 ,并将对象头中的Mark Word复制到锁记录中,官方称为
Displaced Mark Word 。然后线程尝试使用CAS 将对象头中的Mark Word替换为指向锁记录的指针
。如果成功,当前线程获得锁,如果失败,表示其他线程竞争锁,当前线程便尝试使用自旋来获取锁。
解锁
轻量级解锁时,会使用原子的CAS操作将Displaced Mark
Word替换回到对象头,如果成功,则表示没有竞争发生。如果失败,表示当前锁存在竞争,锁就会膨胀成重量级锁。
因为自旋会消耗CPU,为了避免无用的自旋(比如获得锁的线程被阻塞住了),一旦锁升级成重量级锁,就不会再恢复到轻量级锁状态。当锁处于这个状态下,其他线程试图获取锁时,都会被阻塞住,当持有锁的线程释放锁之后会唤醒这些线程,被唤醒的线程就会进行新一轮的夺锁之争。
其他优化
适应性自旋
在使用 CAS 时,如果操作失败,CAS 会自旋再次尝试。由于自旋是需要消耗 CPU 资源的,所以如果长期自旋就白白浪费了
CPU。JDK1.6加入了适应性自旋:
如果某个锁自旋很少成功获得,那么下一次就会减少自旋。
这里还需要提一下,重量级锁是可以降级的,在GC中STW时,
重量级锁的降级发生于STW阶段,降级对象就是那些仅仅能被VMThread访问而没有其他JavaThread访问的对象。
AQS
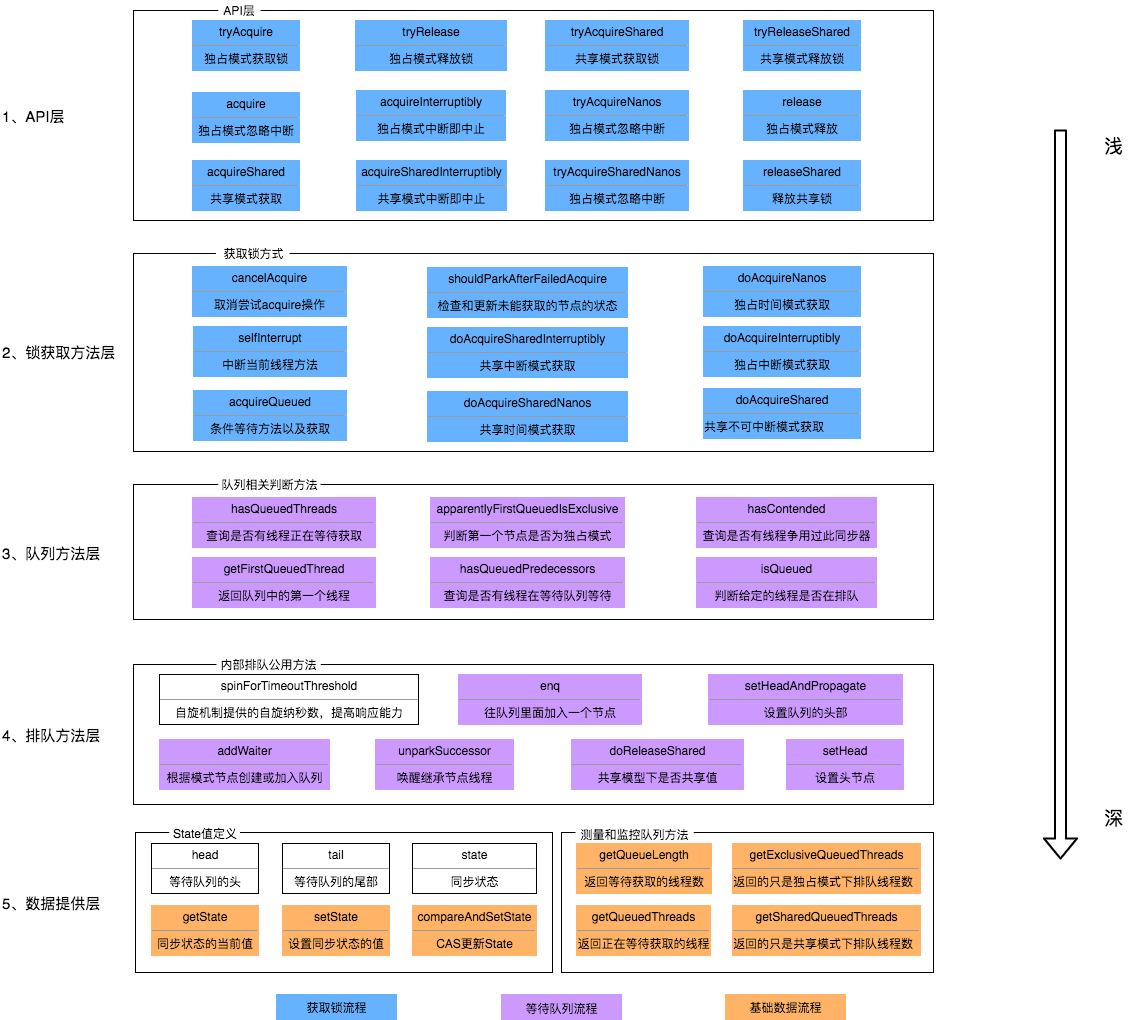
原理概述
AQS核心思想是,如果被请求的共享资源空闲,那么就将当前请求资源的线程设置为有效的工作线程,将共享资源设置为锁定状态;如果共享资源被占用,就需要一定的阻塞等待唤醒机制来保证锁分配。这个机制主要用的是CLH队列的变体实现的,将暂时获取不到锁的线程加入到队列中。
CLH:Craig、Landin and
Hagersten队列,是单向链表,AQS中的队列是CLH变体的虚拟双向队列(FIFO),AQS是通过将每条请求共享资源的线程封装成一个节点来实现锁的分配。
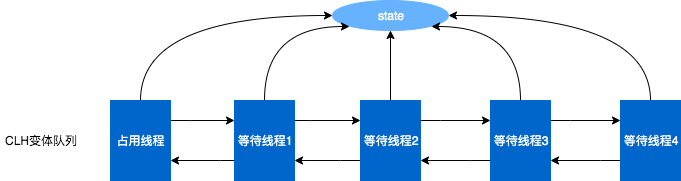
AQS数据结构
// 队列的数据结构如下
// 结点的数据结构
static final class Node {
// 表示该节点等待模式为共享式,通常记录于nextWaiter,
// 通过判断nextWaiter的值可以判断当前结点是否处于共享模式
static final Node SHARED = new Node();
// 表示节点处于独占式模式,与SHARED相对
static final Node EXCLUSIVE = null;
// waitStatus的不同状态,具体内容见下文的表格
static final int CANCELLED = 1;
static final int SIGNAL = -1;
static final int CONDITION = -2;
static final int PROPAGATE = -3;
volatile int waitStatus;
// 记录前置结点
volatile Node prev;
// 记录后置结点
volatile Node next;
// 记录当前的线程
volatile Thread thread;
// 用于记录共享模式(SHARED), 也可以用来记录CONDITION队列(见扩展分析)
Node nextWaiter;
// 通过nextWaiter的记录值判断当前结点的模式是否为共享模式
final boolean isShared() { return nextWaiter == SHARED;}
// 获取当前结点的前置结点
final Node predecessor() throws NullPointerException { ... }
// 用于初始化时创建head结点或者创建SHARED结点
Node() {}
// 在addWaiter方法中使用,用于创建一个新的结点
Node(Thread thread, Node mode) {
this.nextWaiter = mode;
this.thread = thread;
}
// 在CONDITION队列中使用该构造函数新建结点
Node(Thread thread, int waitStatus) {
this.waitStatus = waitStatus;
this.thread = thread;
}
}
// 记录头结点
private transient volatile Node head;
// 记录尾结点
private transient volatile Node tail;
Node状态表(waitStatus,初始化时默认为0)
| 状态名称 |
状态值 |
状态描述 |
| CANCELLED |
1 |
说明当前结点(即相应的线程)是因为超时或者中断取消的,进入该状态后将无法恢复 |
| SIGNAL |
-1 |
|
| 说明当前结点的后继结点是(或者将要)由park导致阻塞的,当结点被释放或者取消时,需要通过unpark唤醒后继结点(表现为unparkSuccessor()方法) |
|
|
| CONDITION |
-2 |
|
| 该状态是用于condition队列结点的,表明结点在等待队列中,结点线程等待在Condition上,当其他线程对Condition调用了signal()方法时,会将其加入到同步队列中去 |
|
|
| PROPAGATE |
-3 |
说明下一次共享式同步状态的获取将会无条件地向后继结点传播 |
AQS的重要方法
从架构图中可以得知,AQS提供了大量用于自定义同步器实现的Protected方法。自定义同步器实现的相关方法也只是为了通过修改State字段来实现多线程的独占模式或者共享模式。自定义同步器需要实现以下方法(并不是全部):
| 方法名 |
描述 |
| protected boolean isHeldExclusively() |
该线程是否正在独占资源。只有用到Condition才需要去实现它。 |
| protected boolean tryAcquire(int arg) |
|
| 独占方式。arg为获取锁的次数,尝试获取资源,成功则返回True,失败则返回False。 |
|
| protected boolean tryRelease(int arg) |
|
| 独占方式。arg为释放锁的次数,尝试释放资源,成功则返回True,失败则返回False。 |
|
| protected int tryAcquireShared(int arg) |
|
| 共享方式。arg为获取锁的次数,尝试获取资源。负数表示失败;0表示成功,但没有剩余可用资源;正数表示成功,且有剩余资源。 |
|
| protected boolean tryReleaseShared(int arg) |
|
| 共享方式。arg为释放锁的次数,尝试释放资源,如果释放后允许唤醒后续等待结点返回True,否则返回False。 |
|
一般来说,自定义同步器要么是独占方式,要么是共享方式,它们也只需实现tryAcquire-tryRelease、tryAcquireShared-
tryReleaseShared中的一种即可。AQS也支持自定义同步器同时实现独占和共享两种方式,如ReentrantReadWriteLock。ReentrantLock是独占锁,所以实现了tryAcquire-
tryRelease。
以非公平锁为例,这里主要阐述一下非公平锁与AQS之间方法的关联之处,具体每一处核心方法的作用会在文章后面详细进行阐述。
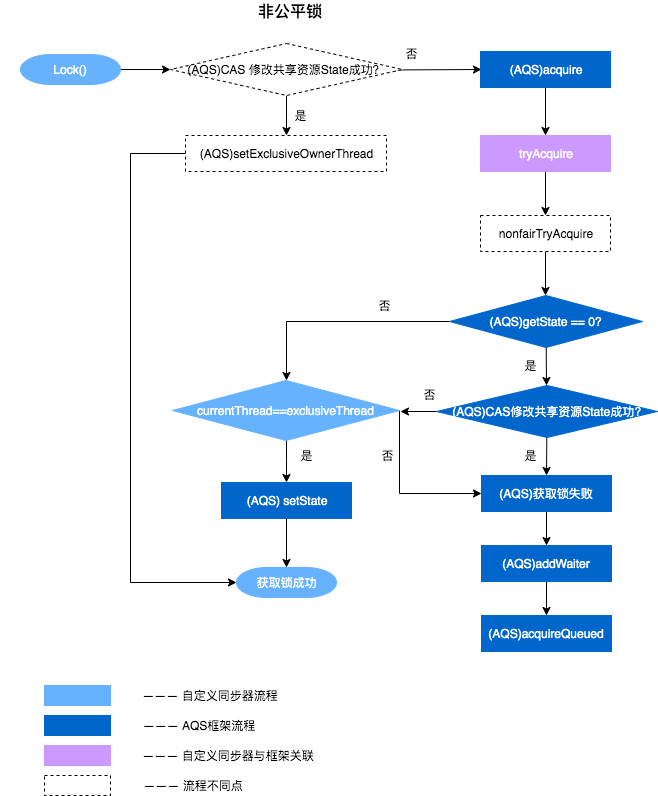
以非公平锁ReentrantLock为例,加锁和解锁的流程如下:
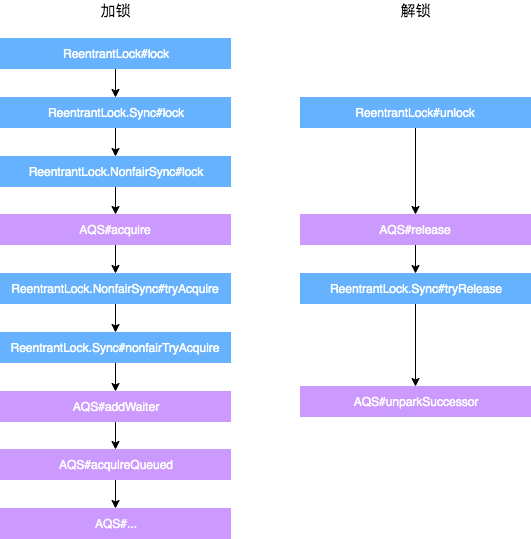
加锁:
- 通过ReentrantLock的加锁方法Lock进行加锁操作。
- 会调用到内部类Sync的Lock方法,由于Sync#lock是抽象方法,根据ReentrantLock初始化选择的公平锁和非公平锁,执行相关内部类的Lock方法,本质上都会执行AQS的Acquire方法。
- AQS的Acquire方法会执行tryAcquire方法,但是由于tryAcquire需要自定义同步器实现,因此执行了ReentrantLock中的tryAcquire方法,由于ReentrantLock是通过公平锁和非公平锁内部类实现的tryAcquire方法,因此会根据锁类型不同,执行不同的tryAcquire。
- tryAcquire是获取锁逻辑,获取失败后,会执行框架AQS的后续逻辑,跟ReentrantLock自定义同步器无关。
解锁:
- 通过ReentrantLock的解锁方法Unlock进行解锁。
- Unlock会调用内部类Sync的Release方法,该方法继承于AQS。
- Release中会调用tryRelease方法,tryRelease需要自定义同步器实现,tryRelease只在ReentrantLock中的Sync实现,因此可以看出,释放锁的过程,并不区分是否为公平锁。
- 释放成功后,所有处理由AQS框架完成,与自定义同步器无关。
acquire方法
// 这里不去看tryAcquire、tryRelease方法的具体实现,只知道它们的作用分别为尝试获取同步状态、尝试释放同步状态
public final void acquire(int arg) {
// 如果线程直接获取成功,或者再尝试获取成功后都是直接工作,
// 如果是从阻塞状态中唤醒开始工作的线程,将当前的线程中断
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
// 包装线程,新建结点并加入到同步队列中
private Node addWaiter(Node mode) {
Node node = new Node(Thread.currentThread(), mode);
Node pred = tail;
// 尝试入队, 成功返回
if (pred != null) {
node.prev = pred;
// CAS操作设置队尾
if (compareAndSetTail(pred, node)) {
pred.next = node;
return node;
}
}
// 通过CAS操作自旋完成node入队操作
enq(node);
return node;
}
}
addWaiter主要的流程如下:
通过当前的线程和锁模式新建一个节点。
Pred指针指向尾节点Tail。
将New中Node的Prev指针指向Pred。
通过compareAndSetTail方法,完成尾节点的设置。这个方法主要是对tailOffset和Expect进行比较,如果tailOffset的Node和Expect的Node地址是相同的,那么设置Tail的值为Update的值。
static {
try {
stateOffset = unsafe.objectFieldOffset(AbstractQueuedSynchronizer.class.getDeclaredField(“state”));
headOffset = unsafe.objectFieldOffset(AbstractQueuedSynchronizer.class.getDeclaredField(“head”));
tailOffset = unsafe.objectFieldOffset(AbstractQueuedSynchronizer.class.getDeclaredField(“tail”));
waitStatusOffset = unsafe.objectFieldOffset(Node.class.getDeclaredField(“waitStatus”));
nextOffset = unsafe.objectFieldOffset(Node.class.getDeclaredField(“next”));
} catch (Exception ex) {
throw new Error(ex);
}
}
从AQS的静态代码块可以看出,都是获取一个对象的属性相对于该对象在内存当中的偏移量,这样我们就可以根据这个偏移量在对象内存当中找到这个属性。tailOffset指的是tail对应的偏移量,所以这个时候会将new出来的Node置为当前队列的尾节点。同时,由于是双向链表,也需要将前一个节点指向尾节点。
如果Pred指针是Null(说明等待队列中没有元素),或者当前Pred指针和Tail指向的位置不同(说明被别的线程已经修改),就需要看一下Enq的方法。
// java.util.concurrent.locks.AbstractQueuedSynchronizer
private Node enq(final Node node) {
for (;;) {
Node t = tail;
if (t == null) { // Must initialize
if (compareAndSetHead(new Node()))
tail = head;
} else {
node.prev = t;
if (compareAndSetTail(t, node)) {
t.next = node;
return t;
}
}
}
}
如果没有被初始化,需要进行初始化一个头结点出来。但请注意,初始化的头结点并不是当前线程节点,而是调用了无参构造函数的节点。如果经历了初始化或者并发导致队列中有元素,则与之前的方法相同。其实,addWaiter就是一个在双端链表添加尾节点的操作,需要注意的是,双端链表的头结点是一个无参构造函数的头结点。
// 在同步队列中等待获取同步状态
final boolean acquireQueued(final Node node, int arg) {
boolean failed = true;
try {
boolean interrupted = false;
// 自旋
for (;;) {
final Node p = node.predecessor();
// 检查是否符合开始工作的条件
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null;
failed = false;
return interrupted;
}
// 获取不到同步状态,将前置结点标为SIGNAL状态并且通过park操作将node包装的线程阻塞
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;
}
} finally {
// 如果获取失败,将node标记为CANCELLED
if (failed)
cancelAcquire(node);
}
//setHead方法是把当前节点置为虚节点,但并没有修改waitStatus,因为它是一直需要用的数据。
private void setHead(Node node) {
head = node;
node.thread = null;
node.prev = null;
}
// java.util.concurrent.locks.AbstractQueuedSynchronizer
// 靠前驱节点判断当前线程是否应该被阻塞
private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) {
// 获取头结点的节点状态
int ws = pred.waitStatus;
// 说明头结点处于唤醒状态
if (ws == Node.SIGNAL)
return true;
// 通过枚举值我们知道waitStatus>0是取消状态
if (ws > 0) {
do {
// 循环向前查找取消节点,把取消节点从队列中剔除
node.prev = pred = pred.prev;
} while (pred.waitStatus > 0);
pred.next = node;
} else {
// 设置前任节点等待状态为SIGNAL
compareAndSetWaitStatus(pred, ws, Node.SIGNAL);
}
return false;
}
parkAndCheckInterrupt主要用于挂起当前线程,阻塞调用栈,返回当前线程的中断状态。
// java.util.concurrent.locks.AbstractQueuedSynchronizer
private final boolean parkAndCheckInterrupt() {
LockSupport.park(this);
return Thread.interrupted();
}
cancelAcquire方法
private void cancelAcquire(Node node) {
// 将无效节点过滤
if (node == null)
return;
// 设置该节点不关联任何线程,也就是虚节点
node.thread = null;
Node pred = node.prev;
// 通过前驱节点,跳过取消状态的node
while (pred.waitStatus > 0)
node.prev = pred = pred.prev;
// 获取过滤后的前驱节点的后继节点
Node predNext = pred.next;
// 把当前node的状态设置为CANCELLED
node.waitStatus = Node.CANCELLED;
// 如果当前节点是尾节点,将从后往前的第一个非取消状态的节点设置为尾节点
// 更新失败的话,则进入else,如果更新成功,将tail的后继节点设置为null
if (node == tail && compareAndSetTail(node, pred)) {
compareAndSetNext(pred, predNext, null);
} else {
int ws;
// 如果当前节点不是head的后继节点,1:判断当前节点前驱节点的是否为SIGNAL,2:如果不是,则把前驱节点设置为SINGAL看是否成功
// 如果1和2中有一个为true,再判断当前节点的线程是否为null
// 如果上述条件都满足,把当前节点的前驱节点的后继指针指向当前节点的后继节点
if (pred != head && ((ws = pred.waitStatus) == Node.SIGNAL || (ws <= 0 && compareAndSetWaitStatus(pred, ws, Node.SIGNAL))) && pred.thread != null) {
Node next = node.next;
if (next != null && next.waitStatus <= 0)
compareAndSetNext(pred, predNext, next);
} else {
// 如果当前节点是head的后继节点,或者上述条件不满足,那就唤醒当前节点的后继节点
unparkSuccessor(node);
}
node.next = node; // help GC
}
}
当前的流程:
- 获取当前节点的前驱节点,如果前驱节点的状态是CANCELLED,那就一直往前遍历,找到第一个waitStatus <= 0的节点,将找到的Pred节点和当前Node关联,将当前Node设置为CANCELLED。
- 根据当前节点的位置,考虑以下三种情况:
(1) 当前节点是尾节点。
(2) 当前节点是Head的后继节点。
(3) 当前节点不是Head的后继节点,也不是尾节点。
执行cancelAcquire的时候,当前节点的前置节点可能已经从队列中出去了(已经执行过Try代码块中的shouldParkAfterFailedAcquire方法了),如果此时修改Prev指针,有可能会导致Prev指向另一个已经移除队列的Node,因此这块变化Prev指针不安全。
shouldParkAfterFailedAcquire方法中,会执行下面的代码,其实就是在处理Prev指针。shouldParkAfterFailedAcquire是获取锁失败的情况下才会执行,进入该方法后,说明共享资源已被获取,当前节点之前的节点都不会出现变化,因此这个时候变更Prev指针比较安全。
do {
node.prev = pred = pred.prev;
} while (pred.waitStatus > 0);
unlock方法
public void unlock() {
sync.release(1);
}
可以看到,本质释放锁的地方,是通过框架来完成的。
// java.util.concurrent.locks.AbstractQueuedSynchronizer
public final boolean release(int arg) {
if (tryRelease(arg)) {
Node h = head;
if (h != null && h.waitStatus != 0)
unparkSuccessor(h);
return true;
}
return false;
}
在ReentrantLock里面的公平锁和非公平锁的父类Sync定义了可重入锁的释放锁机制。
// java.util.concurrent.locks.ReentrantLock.Sync
// 方法返回当前锁是不是没有被线程持有
protected final boolean tryRelease(int releases) {
// 减少可重入次数
int c = getState() - releases;
// 当前线程不是持有锁的线程,抛出异常
if (Thread.currentThread() != getExclusiveOwnerThread())
throw new IllegalMonitorStateException();
boolean free = false;
// 如果持有线程全部释放,将当前独占锁所有线程设置为null,并更新state
if (c == 0) {
free = true;
setExclusiveOwnerThread(null);
}
setState(c);
return free;
}
我们来解释下述源码:
// java.util.concurrent.locks.AbstractQueuedSynchronizer
public final boolean release(int arg) {
// 上边自定义的tryRelease如果返回true,说明该锁没有被任何线程持有
if (tryRelease(arg)) {
// 获取头结点
Node h = head;
// 头结点不为空并且头结点的waitStatus不是初始化节点情况,解除线程挂起状态
if (h != null && h.waitStatus != 0)
unparkSuccessor(h);
return true;
}
return false;
}
这里的判断条件为什么是h != null && h.waitStatus != 0?
h == null Head还没初始化。初始情况下,head ==
null,第一个节点入队,Head会被初始化一个虚拟节点。所以说,这里如果还没来得及入队,就会出现head == null 的情况。
h != null && waitStatus == 0 表明后继节点对应的线程仍在运行中,不需要唤醒。
h != null && waitStatus < 0 表明后继节点可能被阻塞了,需要唤醒。
再看一下unparkSuccessor方法:
// java.util.concurrent.locks.AbstractQueuedSynchronizer
private void unparkSuccessor(Node node) {
// 获取头结点waitStatus
int ws = node.waitStatus;
if (ws < 0)
compareAndSetWaitStatus(node, ws, 0);
// 获取当前节点的下一个节点
Node s = node.next;
// 如果下个节点是null或者下个节点被cancelled,就找到队列最开始的非cancelled的节点
if (s == null || s.waitStatus > 0) {
s = null;
// 就从尾部节点开始找,到队首,找到队列第一个waitStatus<0的节点。
for (Node t = tail; t != null && t != node; t = t.prev)
if (t.waitStatus <= 0)
s = t;
}
// 如果当前节点的下个节点不为空,而且状态<=0,就把当前节点unpark
if (s != null)
LockSupport.unpark(s.thread);
}
为什么要从后往前找第一个非Cancelled的节点呢?原因如下。
之前的addWaiter方法:
// java.util.concurrent.locks.AbstractQueuedSynchronizer
private Node addWaiter(Node mode) {
Node node = new Node(Thread.currentThread(), mode);
// Try the fast path of enq; backup to full enq on failure
Node pred = tail;
if (pred != null) {
node.prev = pred;
if (compareAndSetTail(pred, node)) {
pred.next = node;
return node;
}
}
enq(node);
return node;
}
我们从这里可以看到,节点入队并不是原子操作,也就是说,node.prev = pred; compareAndSetTail(pred, node)
这两个地方可以看作Tail入队的原子操作,但是此时pred.next =
node;还没执行,如果这个时候执行了unparkSuccessor方法,就没办法从前往后找了,所以需要从后往前找。还有一点原因,在产生CANCELLED状态节点的时候,先断开的是Next指针,Prev指针并未断开,因此也是必须要从后往前遍历才能够遍历完全部的Node。
综上所述,如果是从前往后找,由于极端情况下入队的非原子操作和CANCELLED节点产生过程中断开Next指针的操作,可能会导致无法遍历所有的节点。所以,唤醒对应的线程后,对应的线程就会继续往下执行。继续执行acquireQueued方法以后,中断如何处理?
中断恢复后的执行流程
唤醒后,会执行return Thread.interrupted();,这个函数返回的是当前执行线程的中断状态,并清除。
// java.util.concurrent.locks.AbstractQueuedSynchronizer
private final boolean parkAndCheckInterrupt() {
LockSupport.park(this);
return Thread.interrupted();
}
再回到acquireQueued代码,当parkAndCheckInterrupt返回True或者False的时候,interrupted的值不同,但都会执行下次循环。如果这个时候获取锁成功,就会把当前interrupted返回。
// java.util.concurrent.locks.AbstractQueuedSynchronizer
final boolean acquireQueued(final Node node, int arg) {
boolean failed = true;
try {
boolean interrupted = false;
for (;;) {
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null; // help GC
failed = false;
return interrupted;
}
if (shouldParkAfterFailedAcquire(p, node) && parkAndCheckInterrupt())
interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node);
}
}
如果acquireQueued为True,就会执行selfInterrupt方法。
// java.util.concurrent.locks.AbstractQueuedSynchronizer
static void selfInterrupt() {
Thread.currentThread().interrupt();
}
该方法其实是为了中断线程。但为什么获取了锁以后还要中断线程呢?这部分属于Java提供的协作式中断知识内容,感兴趣同学可以查阅一下。这里简单介绍一下:
- 当中断线程被唤醒时,并不知道被唤醒的原因,可能是当前线程在等待中被中断,也可能是释放了锁以后被唤醒。因此我们通过Thread.interrupted()方法检查中断标记(该方法返回了当前线程的中断状态,并将当前线程的中断标识设置为False),并记录下来,如果发现该线程被中断过,就再中断一次。
- 线程在等待资源的过程中被唤醒,唤醒后还是会不断地去尝试获取锁,直到抢到锁为止。也就是说,在整个流程中,并不响应中断,只是记录中断记录。最后抢到锁返回了,那么如果被中断过的话,就需要补充一次中断。
原子类
原子操作是指一个不受其他操作影响的操作任务单元。原子操作是在多线程环境下避免数据不一致必须的手段。
int++并不是一个原子操作,所以当一个线程读取它的值并加 1 时,另外一个线程有可能会读到之前的值,这就会引发错误。
为了解决这个问题,必须保证增加操作是原子的,在 JDK1.5 之前我们可以使用同步技术来做到这一点。到
JDK1.5,java.util.concurrent.atomic 包提供了 int 和long
类型的原子包装类,它们可以自动的保证对于他们的操作是原子的并且不需要使用同步。
java.util.concurrent
这个包里面提供了一组原子类。其基本的特性就是在多线程环境下,当有多个线程同时执行这些类的实例包含的方法时,具有排他性,即当某个线程进入方法,执行其中的指令时,不会被其他线程打断,而别的线程就像自旋锁一样,一直等到该方法执行完成,才由
JVM 从等待队列中选择另一个线程进入,这只是一种逻辑上的理解。
原子类:AtomicBoolean,AtomicInteger,AtomicLong,AtomicReference
原子数组:AtomicIntegerArray,AtomicLongArray,AtomicReferenceArray
原子属性更新器:AtomicLongFieldUpdater,AtomicIntegerFieldUpdater,AtomicReferenceFieldUpdater
解决 ABA 问题的原子类:AtomicMarkableReference(通过引入一个
boolean来反映中间有没有变过),AtomicStampedReference(通过引入一个 int 来累加来反映中间有没有变过)
AtomicInteger举例
public class AtomicInteger extends Number implements java.io.Serializable {
private static final sun.misc.Unsafe U = sun.misc.Unsafe.getUnsafe();
private static final long VALUE;
private volatile int value;//注意该值用volatile修饰
public AtomicInteger(int initialValue) {
value = initialValue;
}
//以原子的方式将输入的值与ActomicInteger中的值进行相加,
//注意:返回相加前ActomicInteger中的值
public final int getAndAdd(int delta) {
return U.getAndAddInt(this, VALUE, delta);
}
//以原子的方式将输入的值与ActomicInteger中的值进行相加,
//注意:返回相加后的结果
public final int addAndGet(int delta) {
return U.getAndAddInt(this, VALUE, delta) + delta;
}
//以原子方式将当前ActomicInteger中的值加1,
//注意:返回相加前ActomicInteger中的值
public final int getAndIncrement() {
return U.getAndAddInt(this, VALUE, 1);
}
//以原子方式将当前ActomicInteger中的值加1,
//注意:返回相加后的结果
public final int incrementAndGet() {
return U.getAndAddInt(this, VALUE, 1) + 1;
}
//省略部分代码...
}
AtomicInteger内部会调用其中sun.misc.Unsafe方法中getAndAddInt的方法。具体代码如下:
public final int getAndAdd(int delta) {
return U.getAndAddInt(this, VALUE, delta);
}
而sun.misc.Unsafe方法中getAndAddInt方法又会调用jdk.internal.misc.Unsafe的getAndAddInt,具体代码如下:
public final int getAndAddInt(Object o, long offset, int delta) {
return theInternalUnsafe.getAndAddInt(o, offset, delta);
}
jdk.internal.misc.Unsafe的getAndAddInt()方法的声明如下:
public final int getAndAddInt(Object o, long offset, int delta) {
int v;
do {
v = getIntVolatile(o, offset);//先获取内存中存储的值
} while (!weakCompareAndSetInt(o, offset, v, v + delta));//如果不是期望的结果值,就一直循环
return v;
}
//该函数返回值代表CAS操作是否成功
public final boolean weakCompareAndSetInt(Object o, long offset,
int expected,
int x) {
return compareAndSetInt(o, offset, expected, x);//执行CAS操作
}
从上述代码中我们可以得出,会先获取内存中存储的值,最终会调用compareAndSetInt()方法来完成最终的原子操作。其中compareAndSetInt()方法的返回值代表着该次CAS操作是否成功。如果不成功。那么会一直循环。直到成功为止(也就是循环CAS操作)。
CountDownLatch
CountDownLatch顾名思义,count + down + latch = 计数 + 减 + 门闩。
可以理解这个东西就是个计数器,只能减不能加,同时它还有个门闩的作用,当计数器不为0时,门闩是锁着的;当计数器减到0时,门闩就打开了。
实现原理
构造方法
下面是实现的源码,非常简短,主要是创建了一个Sync对象。
public CountDownLatch(int count) {
if (count < 0) throw new IllegalArgumentException("count < 0");
this.sync = new Sync(count);
}
Sync对象
private static final class Sync extends AbstractQueuedSynchronizer {
private static final long serialVersionUID = 4982264981922014374L;
Sync(int count) {
setState(count);
}
int getCount() {
return getState();
}
protected int tryAcquireShared(int acquires) {
return (getState() == 0) ? 1 : -1;
}
protected boolean tryReleaseShared(int releases) {
// Decrement count; signal when transition to zero
for (;;) {
int c = getState();
if (c == 0)
return false;
int nextc = c-1;
if (compareAndSetState(c, nextc))
return nextc == 0;
}
}
}
假设我们是这样创建的:new CountDownLatch(5)。其实也就相当于new
Sync(5),相当于setState(5)。setState其实就是共享锁资源总数,我们可以暂时理解为设置一个计数器,当前计数器初始值为5。
tryAcquireShared方法其实就是判断一下当前计数器的值,是否为0了,如果为0的话返回1(
返回1的时候,就表示获取锁成功,awit()方法就不再阻塞 )。
tryReleaseShared方法就是利用CAS的方式,对计数器进行减一的操作,而我们实际上每次调用countDownLatch.countDown()方法的时候,最终都会调到这个方法,对计数器进行减一操作,一直减到0为止。
await()
public void await() throws InterruptedException {
sync.acquireSharedInterruptibly(1);
}
代码很简单,就一句话(注意acquireSharedInterruptibly()方法是抽象类:AbstractQueuedSynchronizer的一个方法,我们上面提到的Sync继承了它),我们跟踪源码,继续往下看:
acquireSharedInterruptibly(int arg)
public final void acquireSharedInterruptibly(int arg)
throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
if (tryAcquireShared(arg) < 0)
doAcquireSharedInterruptibly(arg);
}
源码也是非常简单的,首先判断了一下,当前线程是否有被中断,如果没有的话,就调用tryAcquireShared(int
acquires)方法,判断一下当前线程是否还需要“阻塞”。其实这里调用的tryAcquireShared方法,就是我们上面提到的java.util.concurrent.CountDownLatch.Sync.tryAcquireShared(int)这个方法。
当然,在一开始我们没有调用过countDownLatch.countDown()方法时,这里tryAcquireShared方法肯定是会返回-1的,因为会进入到doAcquireSharedInterruptibly方法。
private void doAcquireSharedInterruptibly(int arg)
throws InterruptedException {
final Node node = addWaiter(Node.SHARED);
boolean failed = true;
try {
for (;;) {
final Node p = node.predecessor();
if (p == head) {
int r = tryAcquireShared(arg);
if (r >= 0) {
setHeadAndPropagate(node, r);
p.next = null; // help GC
failed = false;
return;
}
}
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
throw new InterruptedException();
}
} finally {
if (failed)
cancelAcquire(node);
}
}
countDown()方法
// 计数器减1
public void countDown() {
sync.releaseShared(1);
}
//调用AQS的releaseShared方法
public final boolean releaseShared(int arg) {
if (tryReleaseShared(arg)) {//计数器减一
doReleaseShared();//唤醒后继结点,这个时候队列中可能只有调用过await()的线程节点,也可能队列为空,一般为主线程
return true;
}
return false;
}
//自定义同步器实现的方法
protected boolean tryReleaseShared(int releases) {
// Decrement count; signal when transition to zero
for (;;) {
int c = getState();
if (c == 0)
return false; //重复调用的时候返回false结束上层方法
int nextc = c-1;
if (compareAndSetState(c, nextc))
return nextc == 0; //调用countDown的线程不把资源释放到0,改方法一直返回 false
}
}
这个时候,我们应该对于countDownLatch.await()方法是怎么“阻塞”当前线程的,已经非常明白了。其实说白了,就是当你调用了countDownLatch.await()方法后,你当前线程就会进入了一个死循环当中,在这个死循环里面,会不断的进行判断,通过调用tryAcquireShared方法,不断判断我们上面说的那个计数器,看看它的值是否为0了(为0的时候,其实就是我们调用了足够多
countDownLatch.countDown()方法的时候),如果是为0的话,tryAcquireShared就会返回1,代码也会进入到if (r >=
0)部分,然后跳出了循环,也就不再“阻塞”当前线程了。需要注意的是,说是在不停的循环,其实也并非在不停的执行for循环里面的内容,因为在后面调用parkAndCheckInterrupt()方法时,在这个方法里面是会调用
LockSupport.park(this);来挂起当前线程。
CountDownLatch 使用的注意点:
- 只有当count为0时, await之后的程序才够执行 。
- countDown必须写在finally中,防止发生异程常时,导致程序死锁。
举个栗子
public class Test {
public static void main(String[] args) {
final CountDownLatch latch = new CountDownLatch(2);
new Thread() {
public void run() {
try {
System.out.println("子线程" + Thread.currentThread().getName() + "正在执行");
Thread.sleep(3000);
System.out.println("子线程" + Thread.currentThread().getName() + "执行完毕");
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
latch.countDown();
}
};
}.start();
new Thread() {
public void run() {
try {
System.out.println("子线程" + Thread.currentThread().getName() + "正在执行");
Thread.sleep(3000);
System.out.println("子线程" + Thread.currentThread().getName() + "执行完毕");
latch.countDown();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
latch.countDown();
}
};
}.start();
try {
System.out.println("等待2个子线程执行完毕...");
latch.await();
System.out.println("2个子线程已经执行完毕");
System.out.println("继续执行主线程");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
CyclicBarrier
CyclicBarrier是一个同步辅助类,允许一组线程互相等待,直到到达某个公共屏障点 (common barrier point)。因为该
barrier 在释放等待线程后可以重用,所以称它为循环 的 barrier。
注意比较CountDownLatch和CyclicBarrier:
CountDownLatch的作用是允许1或N个线程等待其他线程完成执行;而CyclicBarrier则是允许N个线程相互等待。
CountDownLatch的计数器无法被重置;CyclicBarrier的计数器可以被重置后使用,因此它被称为是循环的barrier。
CyclicBarrier函数列表
CyclicBarrier(int parties)
创建一个新的 CyclicBarrier,它将在给定数量的参与者(线程)处于等待状态时启动,但它不会在启动 barrier 时执行预定义的操作。
CyclicBarrier(int parties, Runnable barrierAction)
创建一个新的 CyclicBarrier,它将在给定数量的参与者(线程)处于等待状态时启动,并在启动 barrier 时执行给定的屏障操作,该操作由最后一个进入 barrier 的线程执行。
int await()
在所有参与者都已经在此 barrier 上调用 await 方法之前,将一直等待。
int await(long timeout, TimeUnit unit)
在所有参与者都已经在此屏障上调用 await 方法之前将一直等待,或者超出了指定的等待时间。
int getNumberWaiting()
返回当前在屏障处等待参与者数目。
int getParties()
返回要求启动此 barrier 的参与者数目。
boolean isBroken()
查询此屏障是否处于损坏状态。
void reset()
将屏障重置为其初始状态。
CyclicBarrier数据结构
CyclicBarrier的UML类图如下:
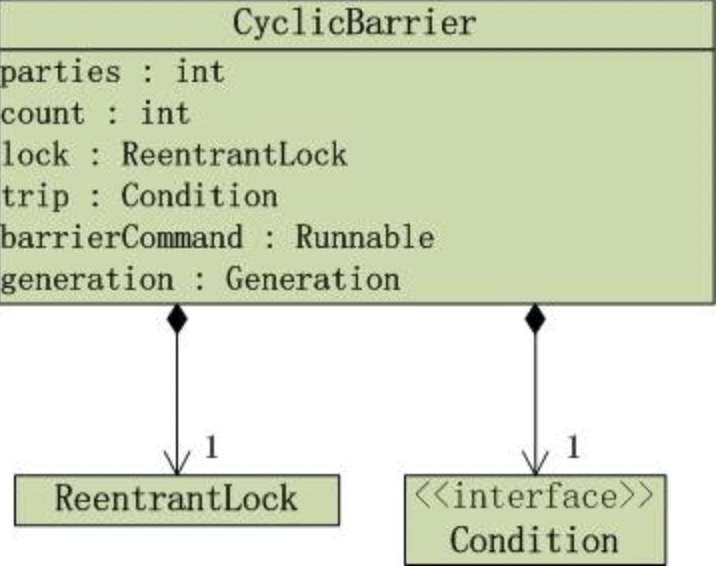
CyclicBarrier是包含了”ReentrantLock对象lock”和”Condition对象trip”,它是通过独占锁实现的。下面通过源码去分析到底是如何实现的。
CyclicBarrier源码分析
构造函数
CyclicBarrier的构造函数共2个:CyclicBarrier 和 CyclicBarrier(int parties, Runnable
barrierAction)。第1个构造函数是调用第2个构造函数来实现的,下面第2个构造函数的源码。
public CyclicBarrier(int parties, Runnable barrierAction) {
if (parties <= 0) throw new IllegalArgumentException();
// parties表示“必须同时到达barrier的线程个数”。
this.parties = parties;
// count表示“处在等待状态的线程个数”。
this.count = parties;
// barrierCommand表示“parties个线程到达barrier时,会执行的动作”。
this.barrierCommand = barrierAction;
}
await()
public int await() throws InterruptedException, BrokenBarrierException {
try {
return dowait(false, 0L);
} catch (TimeoutException toe) {
throw new Error(toe); // cannot happen;
}
}
说明 :await()是通过dowait()实现的。
private int dowait(boolean timed, long nanos)
throws InterruptedException, BrokenBarrierException,
TimeoutException {
final ReentrantLock lock = this.lock;
// 获取“独占锁(lock)”
lock.lock();
try {
// 保存“当前的generation”
final Generation g = generation;
// 若“当前generation已损坏”,则抛出异常。
if (g.broken)
throw new BrokenBarrierException();
// 如果当前线程被中断,则通过breakBarrier()终止CyclicBarrier,唤醒CyclicBarrier中所有等待线程。
if (Thread.interrupted()) {
breakBarrier();
throw new InterruptedException();
}
// 将“count计数器”-1
int index = --count;
// 如果index=0,则意味着“有parties个线程到达barrier”。
if (index == 0) { // tripped
boolean ranAction = false;
try {
// 如果barrierCommand不为null,则执行该动作。
final Runnable command = barrierCommand;
if (command != null)
command.run();
ranAction = true;
// 唤醒所有等待线程,并更新generation。
nextGeneration();
return 0; //这里等价于return index;
} finally {
if (!ranAction)
breakBarrier();
}
}
// 当前线程一直阻塞,直到“有parties个线程到达barrier” 或 “当前线程被中断” 或 “超时”这3者之一发生,
// 当前线程才继续执行。
for (;;) {
try {
// 如果不是“超时等待”,则调用awati()进行等待;否则,调用awaitNanos()进行等待。
if (!timed)
trip.await();
else if (nanos > 0L)
nanos = trip.awaitNanos(nanos);
} catch (InterruptedException ie) {
// 如果等待过程中,线程被中断,则执行下面的函数。
if (g == generation && ! g.broken) {
breakBarrier();
throw ie;
} else {
Thread.currentThread().interrupt();
}
}
// 如果“当前generation已经损坏”,则抛出异常。
if (g.broken)
throw new BrokenBarrierException();
// 如果“generation已经换代”,则返回index。
if (g != generation)
return index;
// 如果是“超时等待”,并且时间已到,则通过breakBarrier()终止CyclicBarrier,唤醒CyclicBarrier中所有等待线程。
if (timed && nanos <= 0L) {
breakBarrier();
throw new TimeoutException();
}
}
} finally {
// 释放“独占锁(lock)”
lock.unlock();
}
}
说明 :dowait()的作用就是让当前线程阻塞,直到“有parties个线程到达barrier” 或 “当前线程被中断” 或
“超时”这3者之一发生,当前线程才继续执行。
(01) generation是CyclicBarrier的一个成员变量,它的定义如下:
private Generation generation = new Generation();
private static class Generation {
boolean broken = false;
}
在CyclicBarrier中,同一批的线程属于同一代,即同一个Generation;CyclicBarrier中通过generation对象,记录属于哪一代。
当有parties个线程到达barrier,generation就会被更新换代。
(02)
如果当前线程被中断,即Thread.interrupted()为true;则通过breakBarrier()终止CyclicBarrier。breakBarrier()的源码如下:
private void breakBarrier() {
generation.broken = true;
count = parties;
trip.signalAll();
}
breakBarrier()会设置当前中断标记broken为true,意味着“将该Generation中断”;同时,设置count=parties,即重新初始化count;最后,通过signalAll()唤醒CyclicBarrier上所有的等待线程。
(03) 将“count计数器”-1,即–count;然后判断是不是“有parties个线程到达barrier”,即index是不是为0。
当index=0时,如果barrierCommand不为null,则执行该barrierCommand,barrierCommand就是我们创建CyclicBarrier时,传入的Runnable对象。然后,调用nextGeneration()进行换代工作,nextGeneration()的源码如下:
private void nextGeneration() {
trip.signalAll();
count = parties;
generation = new Generation();
}
首先,它会调用signalAll()唤醒CyclicBarrier上所有的等待线程;接着,重新初始化count;最后,更新generation的值。
(04)
在for(;;)循环中。timed是用来表示当前是不是“超时等待”线程。如果不是,则通过trip.await()进行等待;否则,调用awaitNanos()进行超时等待。
举个栗子
import java.util.concurrent.CyclicBarrier;
import java.util.concurrent.BrokenBarrierException;
public class CyclicBarrierTest1 {
private static int SIZE = 5;
private static CyclicBarrier cb;
public static void main(String[] args) {
cb = new CyclicBarrier(SIZE);
// 新建5个任务
for(int i=0; i<SIZE; i++)
new InnerThread().start();
}
static class InnerThread extends Thread{
public void run() {
try {
System.out.println(Thread.currentThread().getName() + " wait for CyclicBarrier.");
// 将cb的参与者数量加1
cb.await();
// cb的参与者数量等于5时,才继续往后执行
System.out.println(Thread.currentThread().getName() + " continued.");
} catch (BrokenBarrierException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
运行结果:
Thread-1 wait for CyclicBarrier.
Thread-2 wait for CyclicBarrier.
Thread-3 wait for CyclicBarrier.
Thread-4 wait for CyclicBarrier.
Thread-0 wait for CyclicBarrier.
Thread-0 continued.
Thread-4 continued.
Thread-2 continued.
Thread-3 continued.
Thread-1 continued.
import java.util.concurrent.CyclicBarrier;
import java.util.concurrent.BrokenBarrierException;
public class CyclicBarrierTest2 {
private static int SIZE = 5;
private static CyclicBarrier cb;
public static void main(String[] args) {
cb = new CyclicBarrier(SIZE, new Runnable () {
public void run() {
System.out.println("CyclicBarrier's parties is: "+ cb.getParties());
}
});
// 新建5个任务
for(int i=0; i<SIZE; i++)
new InnerThread().start();
}
static class InnerThread extends Thread{
public void run() {
try {
System.out.println(Thread.currentThread().getName() + " wait for CyclicBarrier.");
// 将cb的参与者数量加1
cb.await();
// cb的参与者数量等于5时,才继续往后执行
System.out.println(Thread.currentThread().getName() + " continued.");
} catch (BrokenBarrierException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
运行结果:
Thread-1 wait for CyclicBarrier.
Thread-2 wait for CyclicBarrier.
Thread-3 wait for CyclicBarrier.
Thread-4 wait for CyclicBarrier.
Thread-0 wait for CyclicBarrier.
CyclicBarrier's parties is: 5
Thread-0 continued.
Thread-4 continued.
Thread-2 continued.
Thread-3 continued.
Thread-1 continued.
Semaphore
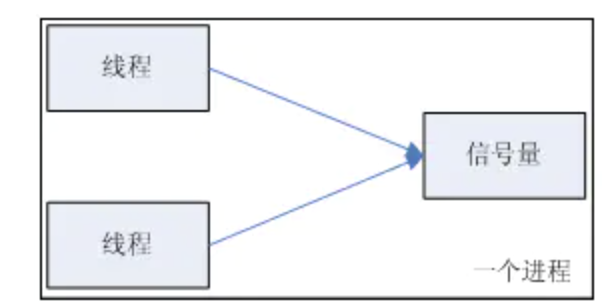
我们以一个停车场运作为例来说明信号量的作用。假设停车场只有三个车位,一开始三个车位都是空的。这时如果同时来了三辆车,看门人允许其中它们进入,然后放下车拦。以后来的车必须在入口等待,直到停车场中有车辆离开。这时,如果有一辆车离开停车场,看门人得知后,打开车拦,放入一辆,如果又离开一辆,则又可以放入一辆,如此往复。
在这个停车场系统中,车位是公共资源,每辆车好比一个线程,看门人起的就是信号量的作用。信号量是一个非负整数,表示了当前公共资源的可用数目(在上面的例子中可以用空闲的停车位类比信号量),当一个线程要使用公共资源时(在上面的例子中可以用车辆类比线程),首先要查看信号量,如果信号量的值大于1,则将其减1,然后去占有公共资源。如果信号量的值为0,则线程会将自己阻塞,直到有其它线程释放公共资源
在信号量上我们定义两种操作: acquire(获取) 和
release(释放)。当一个线程调用acquire操作时,它要么通过成功获取信号量(信号量减1),要么一直等下去,直到有线程释放信号量,或超时。release(释放)实际上会将信号量的值加1,然后唤醒等待的线程。
信号量主要用于两个目的,一个是用于多个共享资源的互斥使用,另一个用于并发线程数的控制。
源码解析
在Java的并发包中,Semaphore类表示信号量。Semaphore内部主要通过AQS(AbstractQueuedSynchronizer)实现线程的管理。Semaphore有两个构造函数,
参数permits表示许可数 ,它最后传递给了AQS的state值。线程在运行时首先获取许可, 如果成功,许可数就减1
,线程运行,当线程运行结束就释放许可, 许可数就加1
。如果许可数为0,则获取失败,线程位于AQS的等待队列中,它会被其它释放许可的线程唤醒。在创建Semaphore对象的时候还可以指定它的公平性。一般常用非公平的信号量,非公平信号量是指在获取许可时先尝试获取许可,而不必关心是否已有需要获取许可的线程位于等待队列中,如果获取失败,才会入列。而公平的信号量在获取许可时首先要查看等待队列中是否已有线程,如果有则入列。
构造函数
//非公平的构造函数
public Semaphore(int permits) {
sync = new NonfairSync(permits);
}
//通过fair参数决定公平性
public Semaphore(int permits, boolean fair) {
sync = fair ? new FairSync(permits) : new NonfairSync(permits);
}
acquire()
public void acquire() throws InterruptedException {
sync.acquireSharedInterruptibly(1);
}
public final void acquireSharedInterruptibly(int arg)
throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
if (tryAcquireShared(arg) < 0)
doAcquireSharedInterruptibly(arg);
}
- 调用tryAcquireShared()方法尝试获取信号。
- 如果没有可用信号,将当前线程加入等待队列并挂起
tryAcquireShared
会调用对应公平或者非公平同步器的方法,xxTAcquireShared下面是非公平的,公平的方法就多了一个hasQueuedPredecessors方法的逻辑
NonfairSync.tryAcquireShared()
final int nonfairTryAcquireShared(int acquires) {
for (;;) {
int available = getState();
int remaining = available - acquires; //剩余许可数
if (remaining < 0 ||
compareAndSetState(available, remaining))
return remaining;
}
}
可以看出,如果remaining <0
即获取许可后,许可数小于0,则获取失败,在doAcquireSharedInterruptibly方法中线程会将自身阻塞,然后入列。可以看到,非公平锁对于信号的获取是直接使用CAS进行尝试的。
FairSync.tryAcquireShared()
protected int tryAcquireShared(int acquires) {
for (;;) {
if (hasQueuedPredecessors())
return -1;
int available = getState();
int remaining = available - acquires;
if (remaining < 0 ||
compareAndSetState(available, remaining))
return remaining;
}
}
doAcquireSharedInterruptibly()
private void doAcquireSharedInterruptibly(int arg)
throws InterruptedException {
final Node node = addWaiter(Node.SHARED); // 1
boolean failed = true;
try {
for (;;) {
final Node p = node.predecessor();
if (p == head) { // 2
int r = tryAcquireShared(arg);
if (r >= 0) {
setHeadAndPropagate(node, r);
p.next = null; // help GC
failed = false;
return;
}
}
if (shouldParkAfterFailedAcquire(p, node) && // 3
parkAndCheckInterrupt())
throw new InterruptedException();
}
} finally {
if (failed)
cancelAcquire(node);
}
}
- 封装一个Node节点,加入队列尾部
- 在无限循环中,如果当前节点是头节点,就尝试获取信号
- 不是头节点,在经过节点状态判断后,挂起当前线程
release()释放信号
public final boolean releaseShared(int arg) {
if (tryReleaseShared(arg)) { // 1
doReleaseShared(); // 2
return true;
}
return false;
}
- cas更新state加一
- 唤醒等待队列头节点线程
举个栗子
public static void main(String[] args) {
ThreadPoolExecutor threadPool = new ThreadPoolExecutor(10, 10,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(10));
//信号总数为5
Semaphore semaphore = new Semaphore(5);
//运行10个线程
for (int i = 0; i < 10; i++) {
threadPool.execute(new Runnable() {
@Override
public void run() {
try {
//获取信号
semaphore.acquire();
System.out.println(Thread.currentThread().getName() + "获得了信号量,时间为" + System.currentTimeMillis());
//阻塞2秒,测试效果
Thread.sleep(2000);
System.out.println(Thread.currentThread().getName() + "释放了信号量,时间为" + System.currentTimeMillis());
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
//释放信号
semaphore.release();
}
}
});
}
threadPool.shutdown();
}
pool-1-thread-2获得了信号量,时间为1550584196125
pool-1-thread-1获得了信号量,时间为1550584196125
pool-1-thread-3获得了信号量,时间为1550584196125
pool-1-thread-4获得了信号量,时间为1550584196126
pool-1-thread-5获得了信号量,时间为1550584196127
pool-1-thread-2释放了信号量,时间为1550584198126
pool-1-thread-3释放了信号量,时间为1550584198126
pool-1-thread-4释放了信号量,时间为1550584198126
pool-1-thread-6获得了信号量,时间为1550584198126
pool-1-thread-9获得了信号量,时间为1550584198126
pool-1-thread-8获得了信号量,时间为1550584198126
pool-1-thread-1释放了信号量,时间为1550584198126
pool-1-thread-10获得了信号量,时间为1550584198126
pool-1-thread-5释放了信号量,时间为1550584198127
pool-1-thread-7获得了信号量,时间为1550584198127
pool-1-thread-6释放了信号量,时间为1550584200126
pool-1-thread-8释放了信号量,时间为1550584200126
pool-1-thread-10释放了信号量,时间为1550584200126
pool-1-thread-9释放了信号量,时间为1550584200126
pool-1-thread-7释放了信号量,时间为1550584200127